サーバーレスのイベント駆動型ワークフローを作成! AWS Glue と Amazon EventBridgeでやってみた【後編】 (1)
ようこそ、IoTに関する技術的な内容を紹介するコネクシオのテックブログへ!
コネクシオでは、お客様にクラウド環境とセットでIoTソリューションを数多くご提供しており、その中で、IoTゲートウェイが収集した環境データを、より効果的に可視化・分析するために、クラウド側でデータを加工することがあります。
IoTゲートウェイから送信されるデータをそのままクラウドで扱いやすく加工することも可能ですが、ゲートウェイで保持していないデータを付加したり、ユーザーの可視化・分析基盤に適した形式に調整したりする場合、クラウド側でのデータ加工が必要となります。
今回は、AWS Glue と Amazon EventBridge を使用して取り込んで処理するサーバーレスのイベント駆動型ワークフローを作成して、Amazon QuickSightで可視化までを行う例を前編後編に分け、じっくりとご紹介します。
後編となる今回を一読いただき、IoTデータ活用を始めたり、見直すきっかけになれば幸いです!
目次[非表示]
- 1.はじめに
- 2.加工データ
- 3.前提条件
- 4.やってみよう
- 4.1.Athenaクエリ実行の準備
- 4.2.QuickSightの準備
- 4.3.実行確認
- 5.まとめ
▼オススメ関連記事
「工事不要でIoTをお手軽導入!「EDConnectワイヤレス」とは? 」
「IoTに必須のIoTセンサの種類と特長、活用事例を解説 」
はじめに
後編では、Athenaでのクエリ結果をQuickSightで可視化するための準備と動作確認の手順をご紹介します。
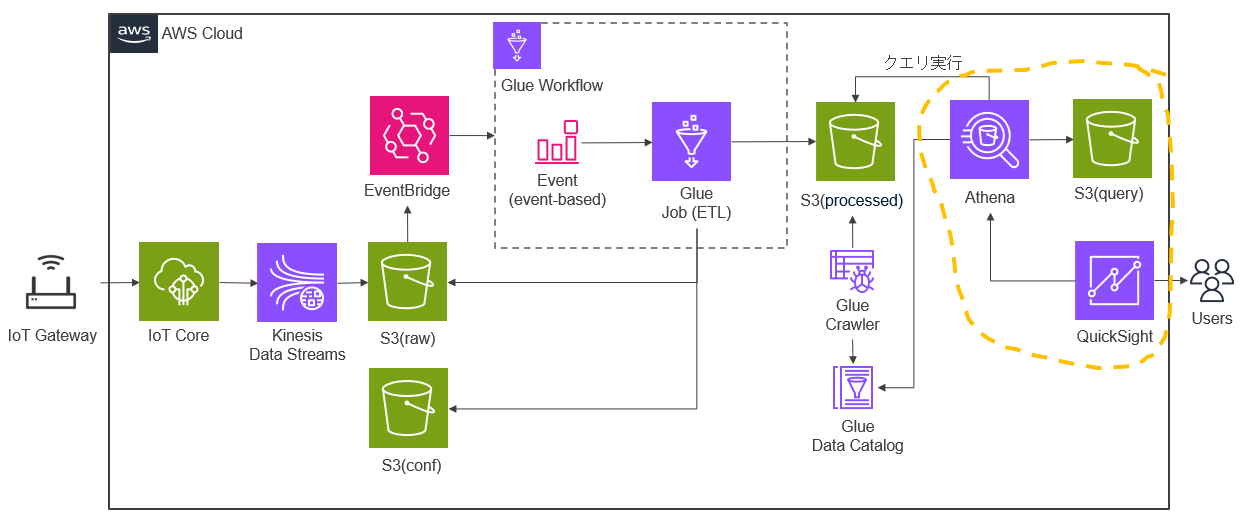
今回は以下のような構成でAWSのリソースを準備し、IoTゲートウェイから収集した環境データを AWS Glue と Amazon EventBridge を使用してデータを加工して取り込み、Athenaでのクエリ結果をQuickSightで可視化します。前編ではデータ加工の準備と、そのデータ加工をイベントで起動するための準備を行いました。後編ではAthenaでのクエリ結果をQuickSightで可視化するための準備を行い、動作確認をします。
▼前編はこちら
「サーバーレスのイベント駆動型ワークフローを作成!AWS Glue と Amazon EventBridgeでやってみた【前編】」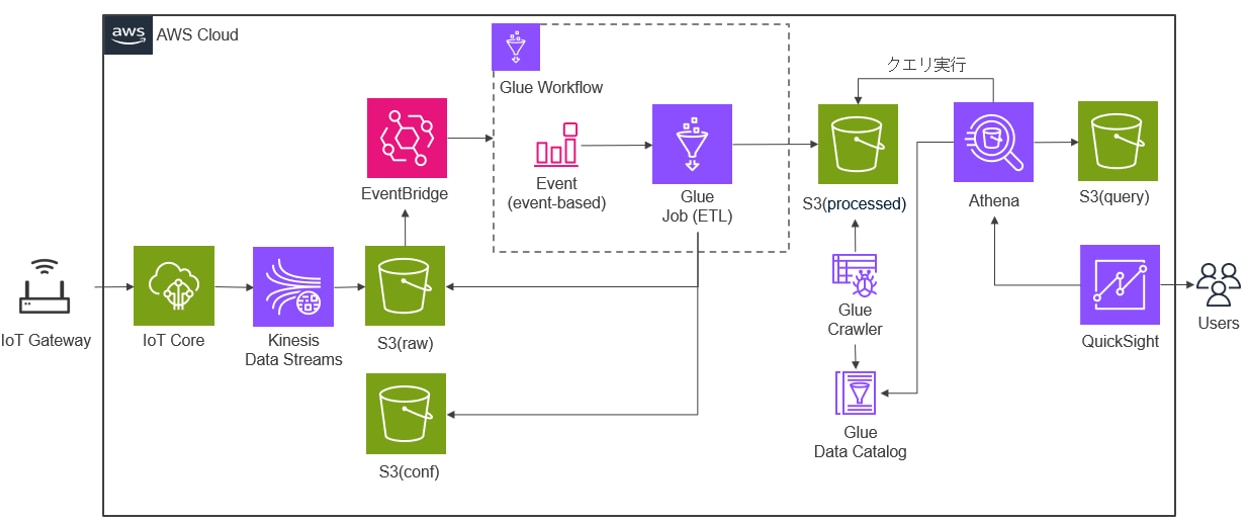
加工データ
今回行うデータの加工は以下のような内容になります。IoTゲートウェイから受信した内容に、クラウド側で持つGW設定ファイルの内容からdeviceIdに紐づく設備情報を付加してCSVファイルを作成します。この加工データ(CSV)に対してAthenaで実行したクエリ結果をQuickSightで可視化します。

前提条件
・IoT Coreによるデバイス認証、モノの登録ができている。
・IoT Coreで取得した情報をKinesis Data FirehoseでまとめてS3に保存するための設定。
・Sバケット、フォルダ作成および、必要ファイルの格納。
・QuickSightのアカウント登録
・Athenaのクエリ結果の場所の設定
・IoTゲートウェイが各種センサーから収集した環境データをIoT Coreへ送信するための設定。
また、今回は各サービスについての説明については割愛しています。
やってみよう
Athenaクエリ実行の準備
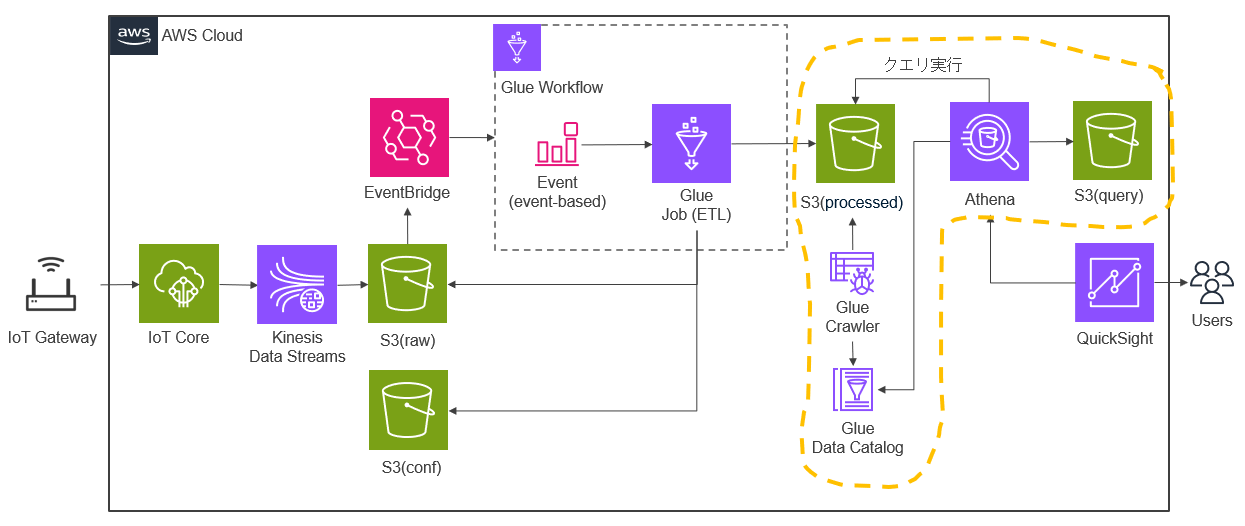
以下のデータカタログ、クローラー、Athena部分の準備を行います。S3(processed)の加工データ(CSV)に対してAthenaでクエリを実行して、クエリ結果をS3(query)に保存します。
・Glueデータカタログの作成
Glueコンソールを開き、[Data Catalog][Databases]「Add databases」をクリックします。
以下を設定し、「Create database 」をクリックします。
Name:任意のデータベース名。(例:env-data-db)
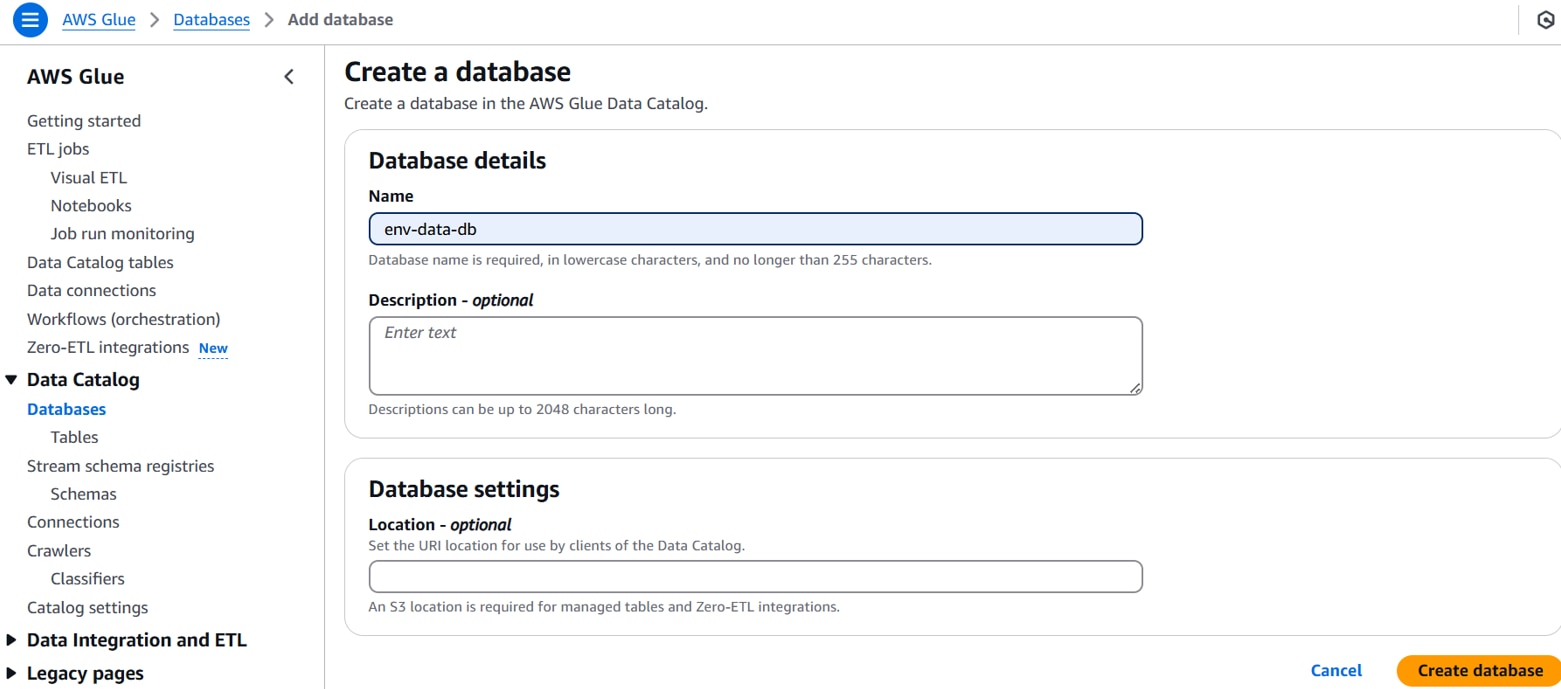
データカタログデータベースが作成されます。
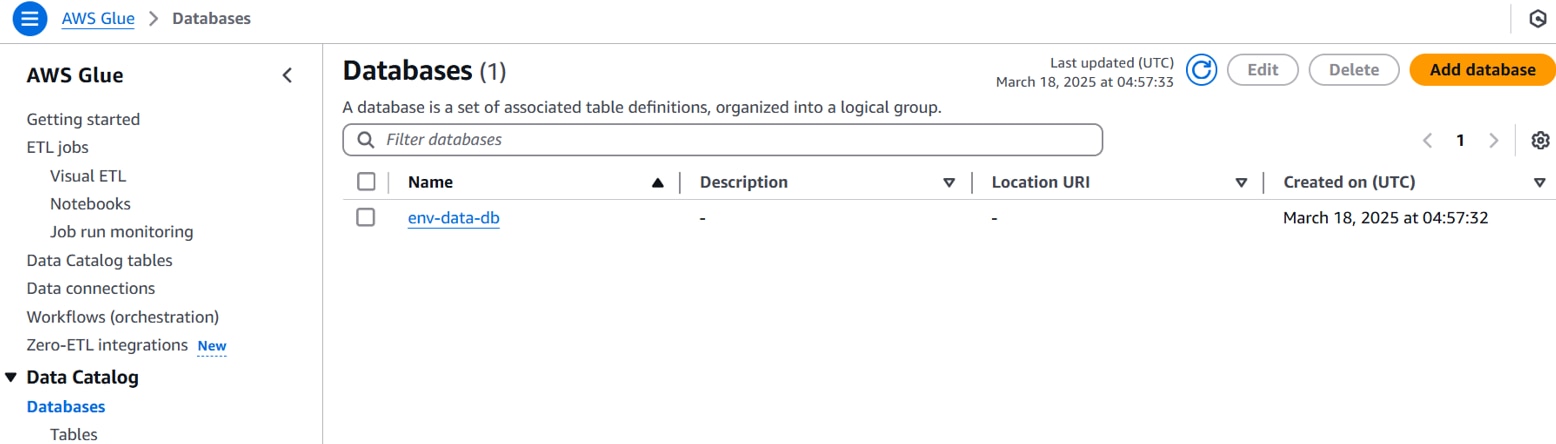
[Data Catalog][Databases][Tables]「Add table」をクリックします。
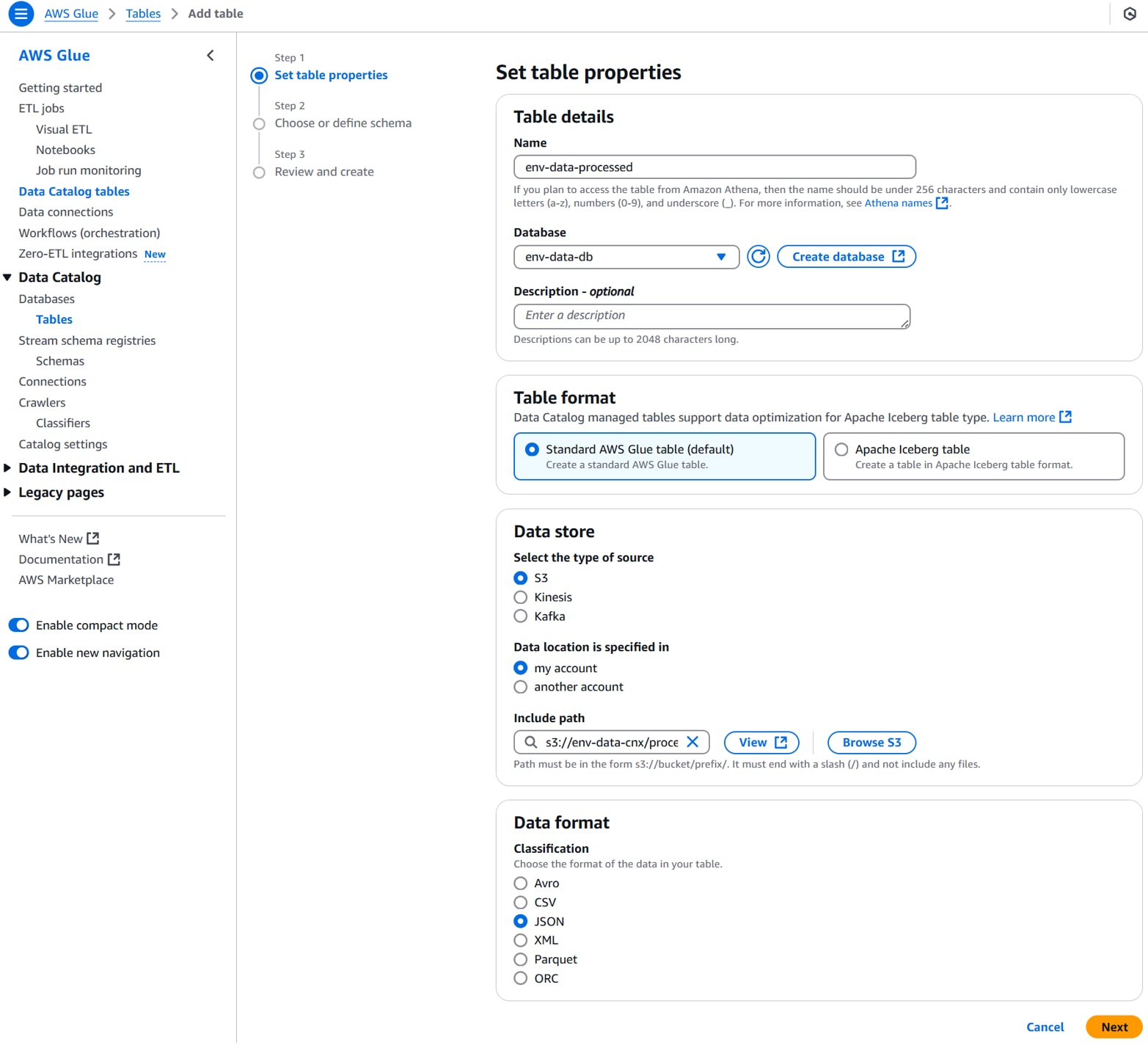
以下を設定し、「Next」をクリックします。
Name:任意のテーブル名。(例:env-data-processed)
Database:任意のデータベース名。(例:env-data-db)
Data store(type):S3
Data store(location):my account
Data store(Include path):任意のS3バケットフォルダパス。(例:s3://env-data-cnx/processed/)
Data format:任意のデータフォーマット。(例:JSON)
デフォルト設定のまま「Next」をクリックします。
内容を確認して、「Create」をクリックします。
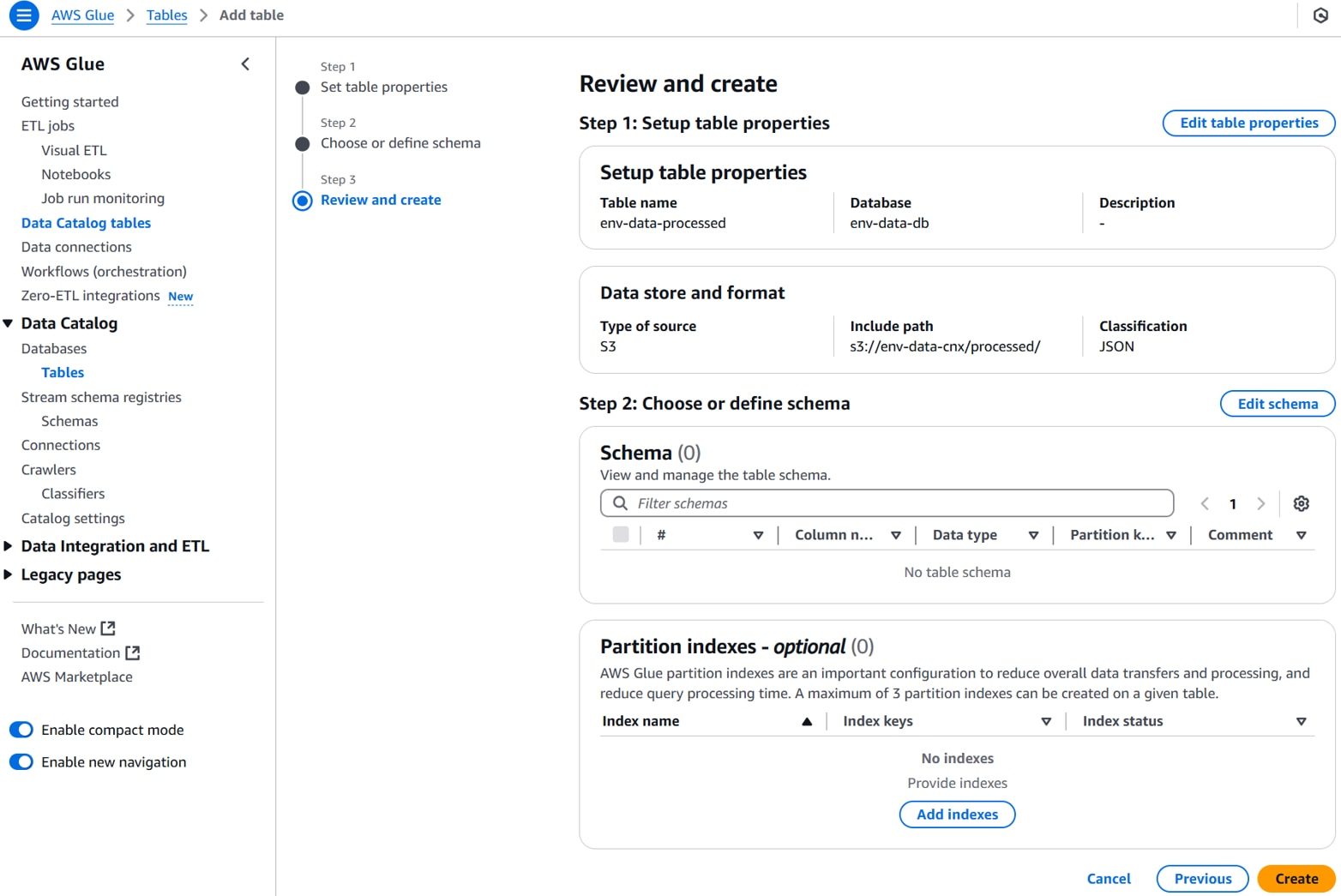
データカタログテーブルが作成されます。
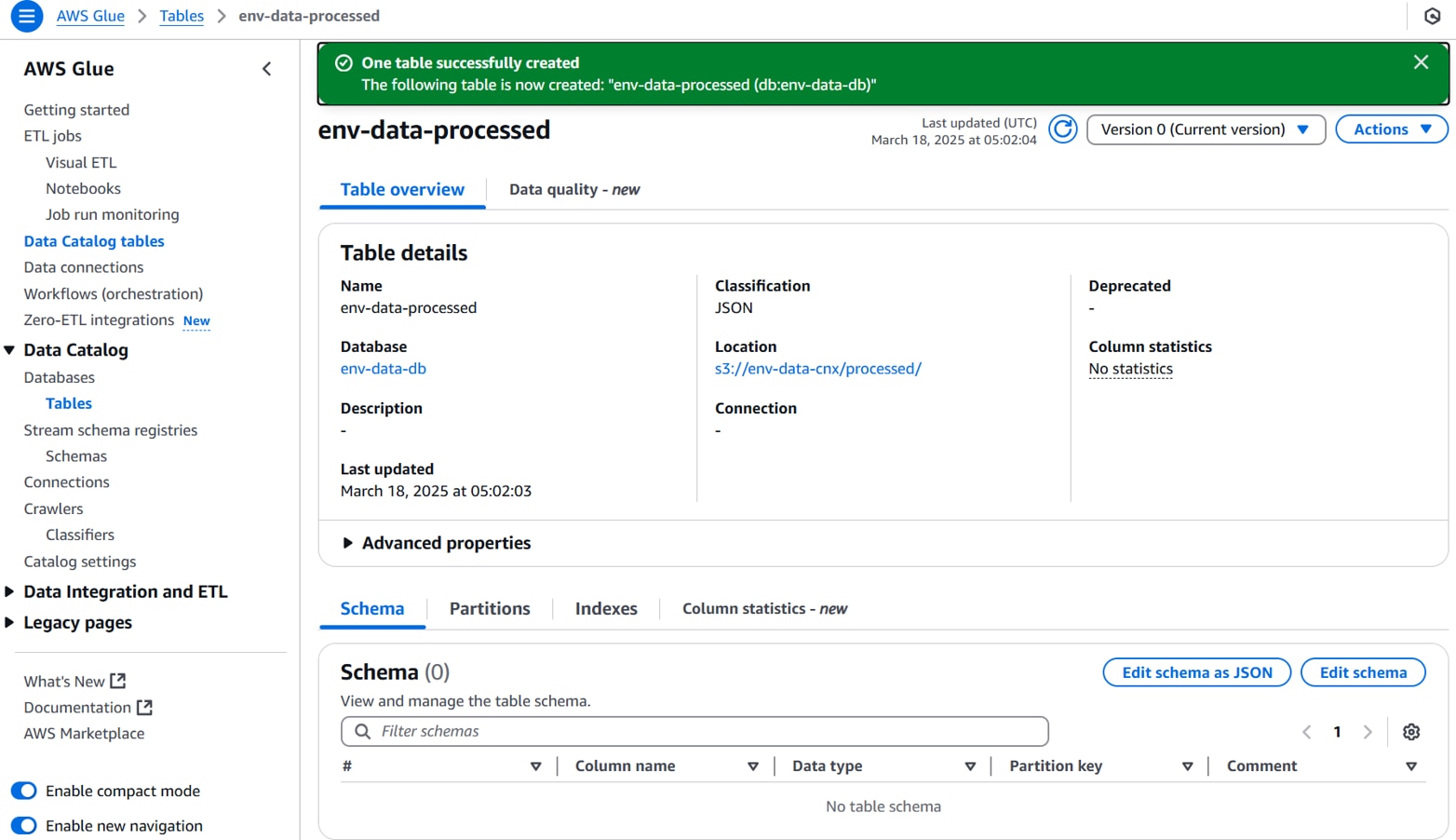
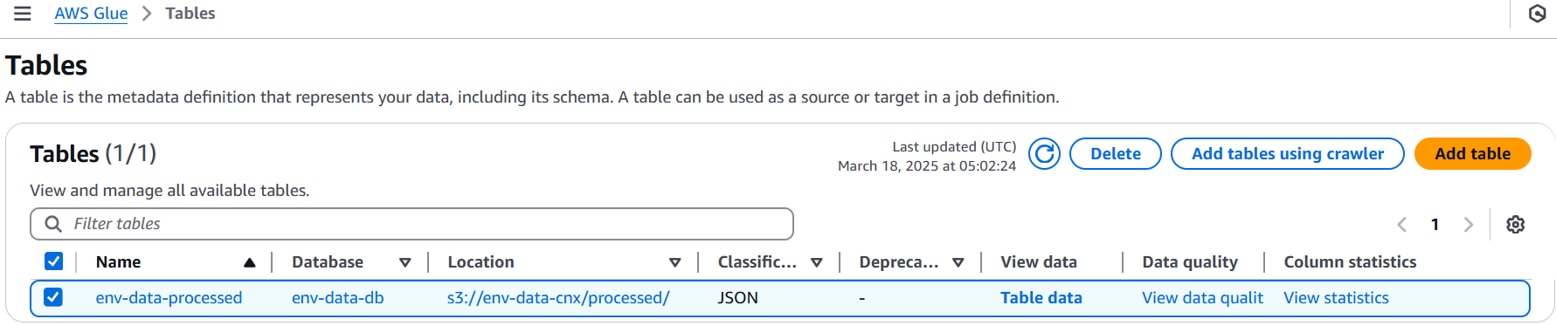
・Glueクローラーの作成
Glueコンソールを開き、[Data Catalog][Crawlers]「Create crawler」をクリックします。
以下を設定し、「Next」をクリックします。
Name:任意のクローラー名。(例:env-data-cw)
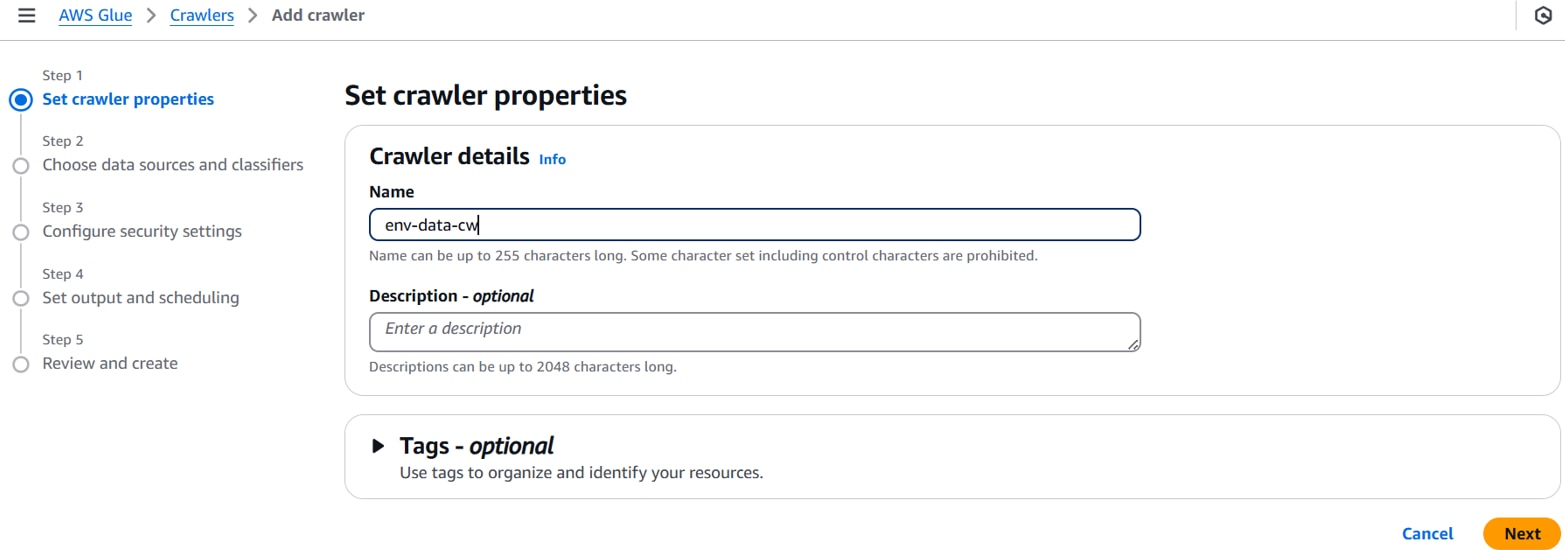
以下を設定し、「Add tables」をクリックします。
Data source configuration:Yes
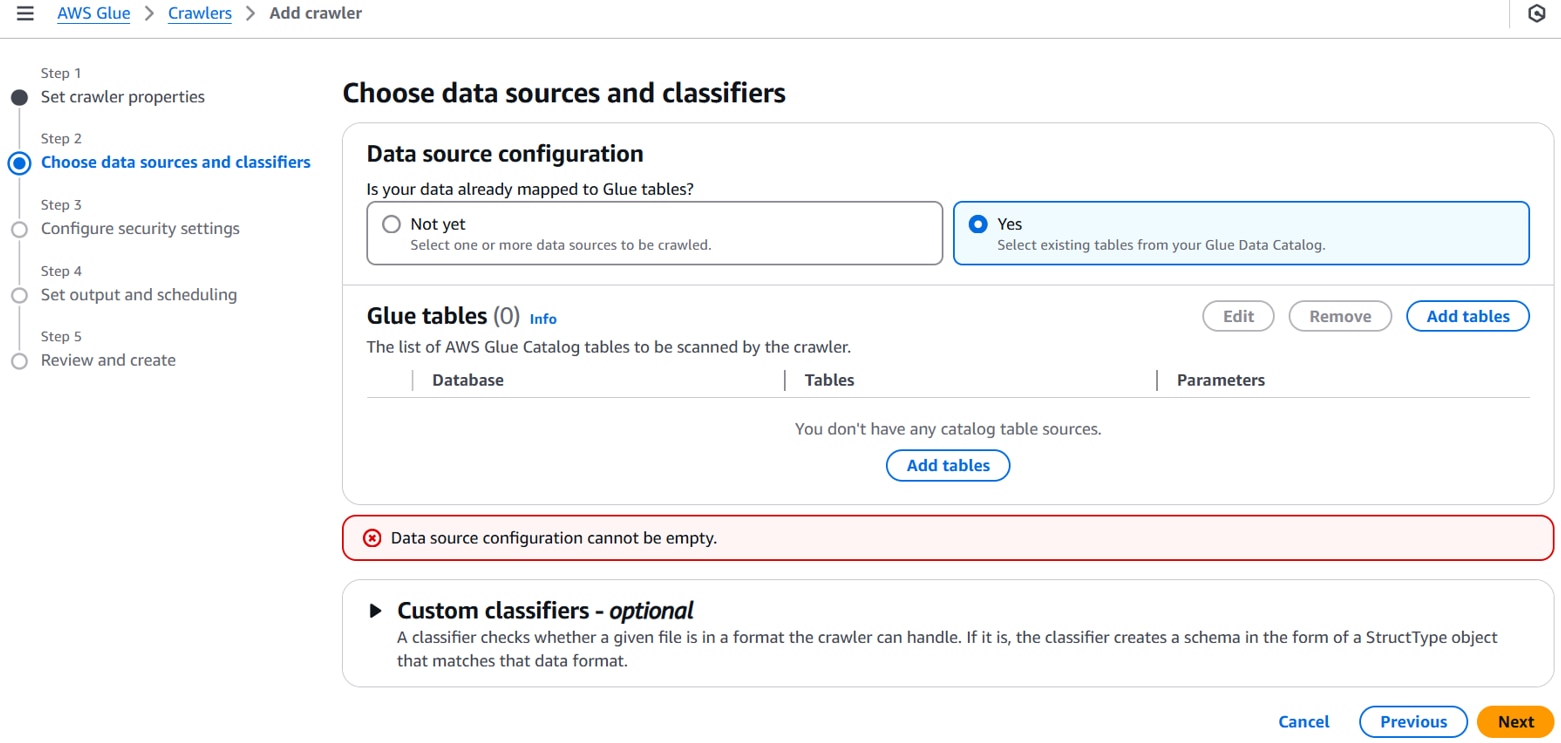
以下を設定し、「Confirm」をクリックします。
Database:任意のデータベース。(例:env-data-db)
Tables:任意のテーブル。(例:env-data-processed)
Subsequent crawler runs:Crawl all sub-folders
内容を確認し、「Next」をクリックします。
「Create new IAM role」をクリックします。
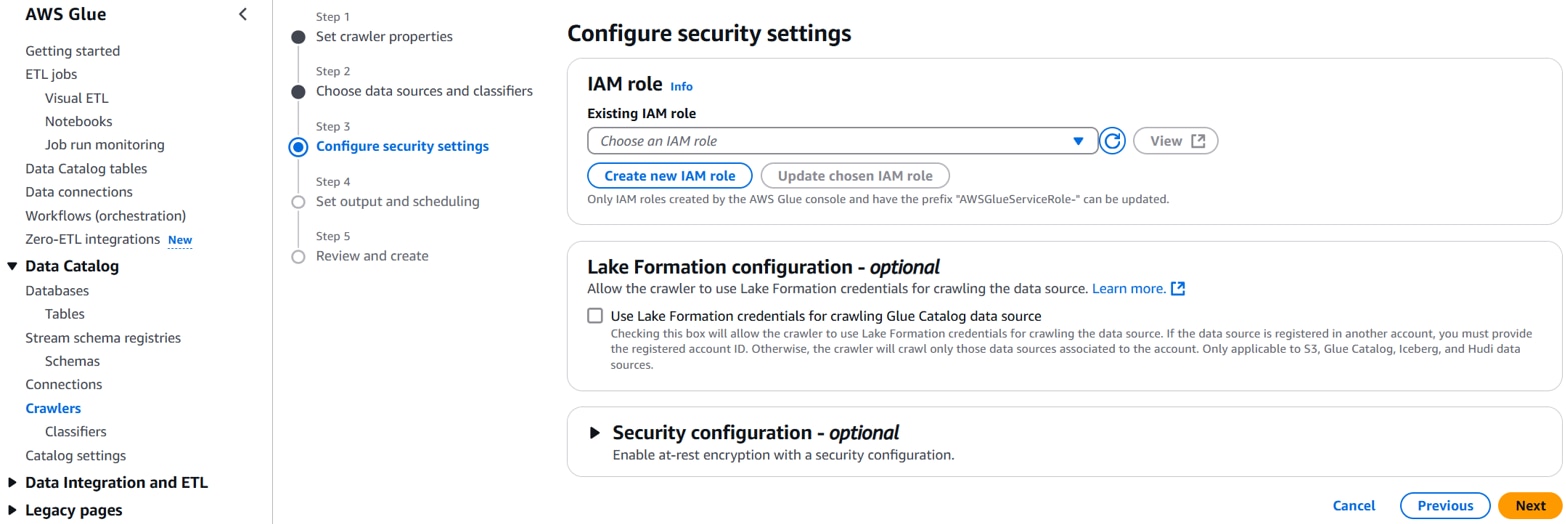
以下を設定し、「Create」をクリックします。
Enter new IAM role:任意のIAMロール名。(例:AWSGlueServiceRole-env-data)

以下を設定し、「View」をクリックします。
Existing IAM role:任意のIAMロール名。(例:AWSGlueServiceRole-env-data)
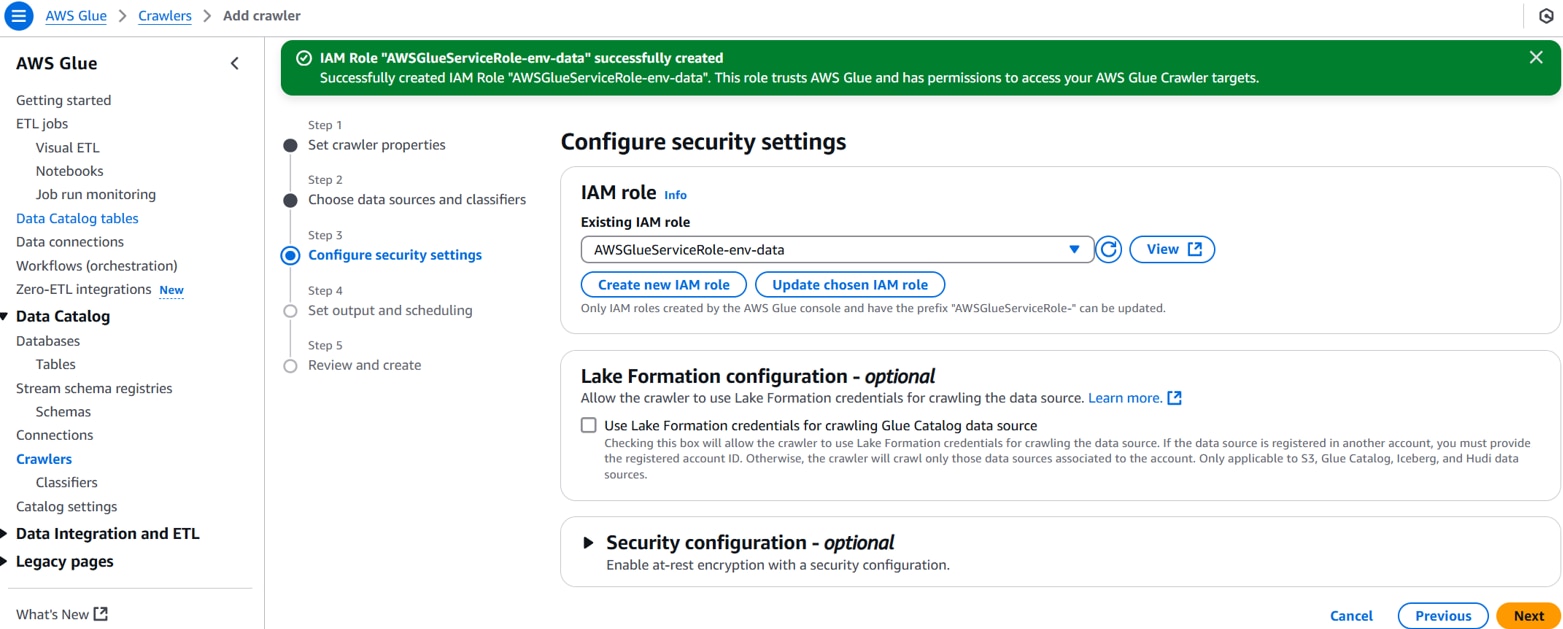
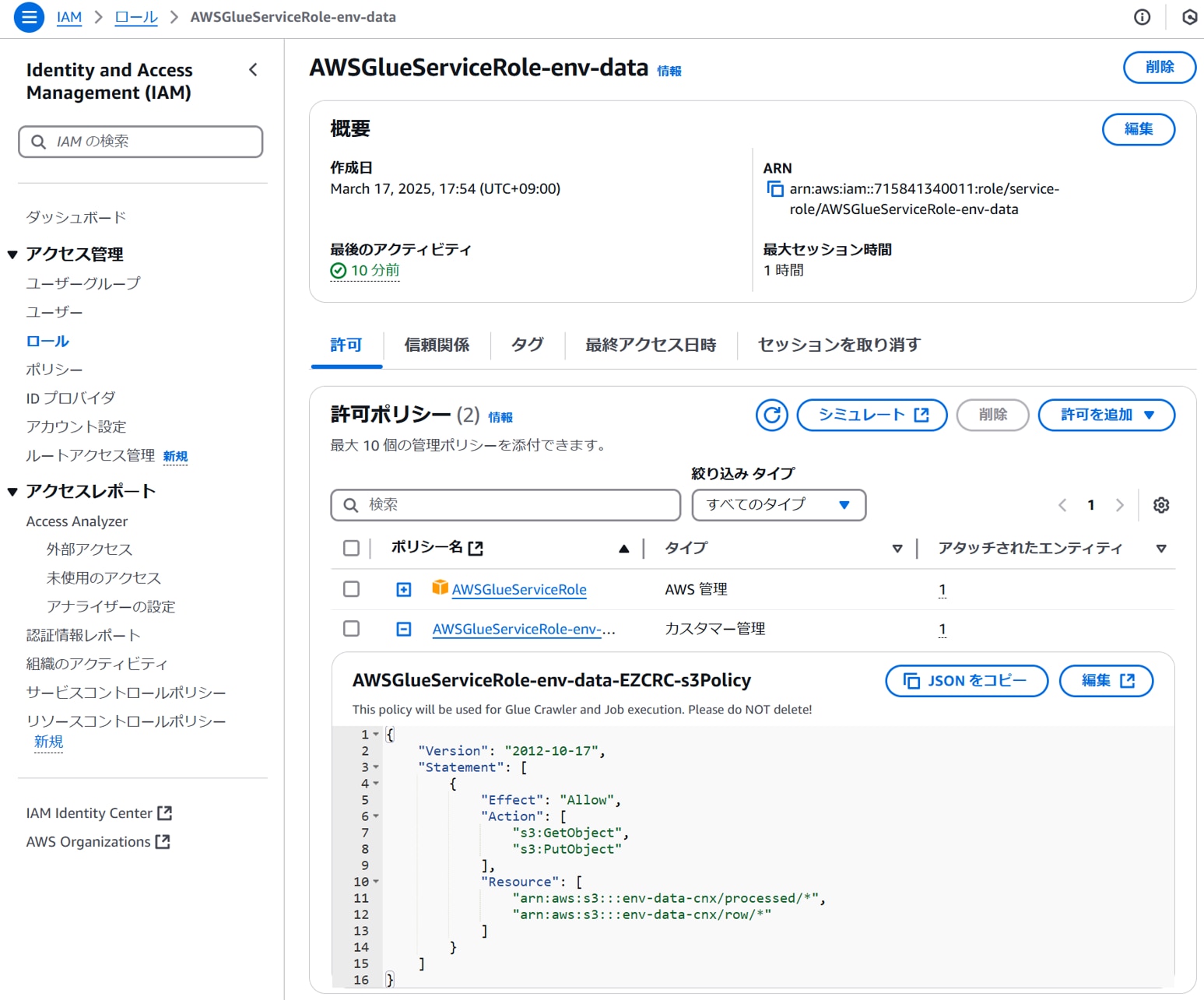
IAMロールに、必要なS3へのアクセス許可ポリシーが付与されていることを確認する。
以下を設定し、「Next」をクリックします。
Existing IAM role:任意のIAMロール名。(例:AWSGlueServiceRole-env-data)
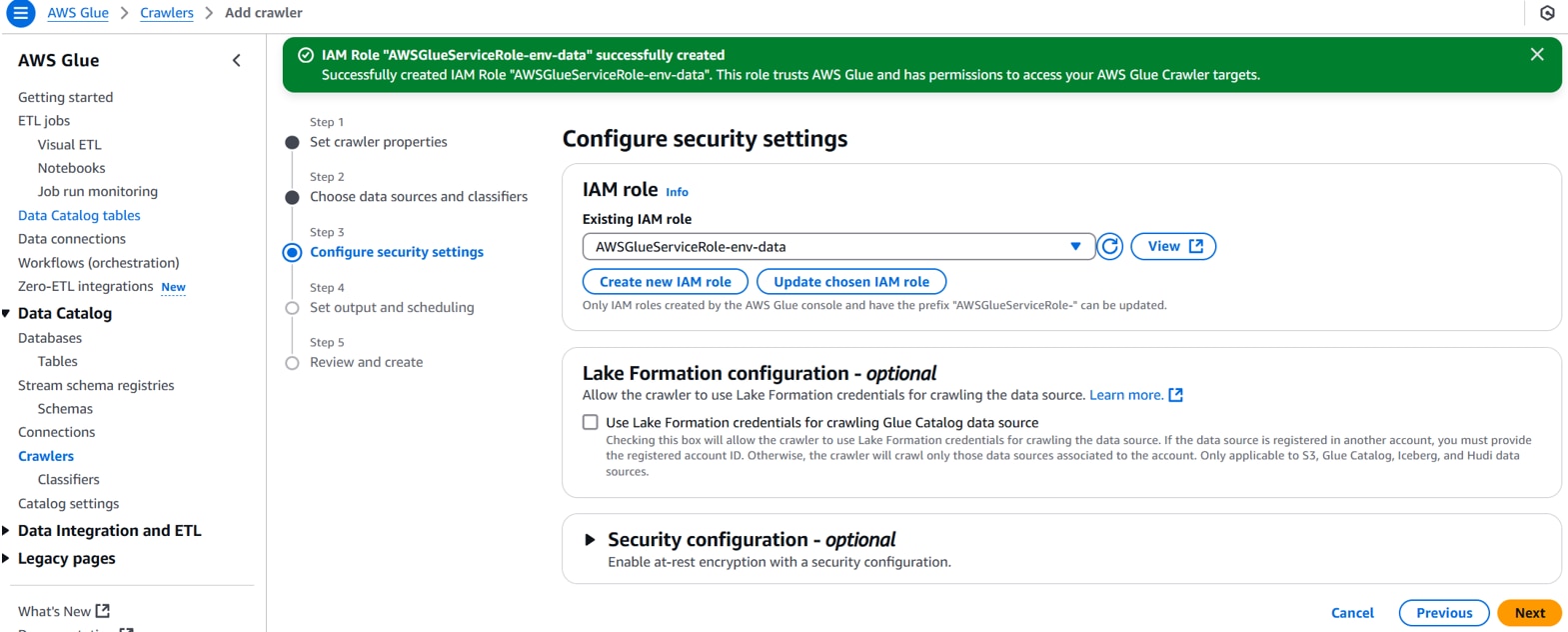
以下を設定し、「Next」をクリックします。
Crawler shedule(Frequency):On demand

内容を確認し、「Create crawler」をクリックします。

クローラーが作成されます。
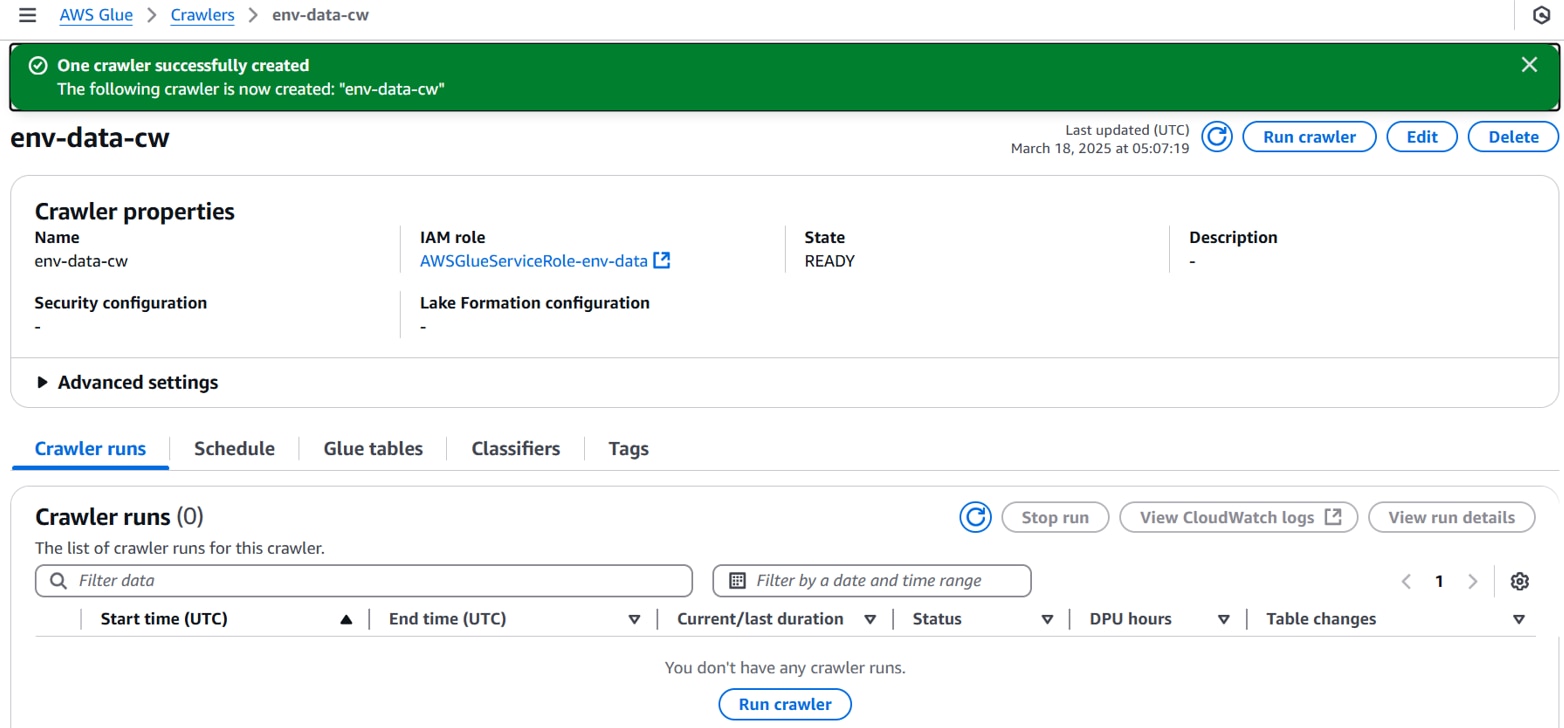
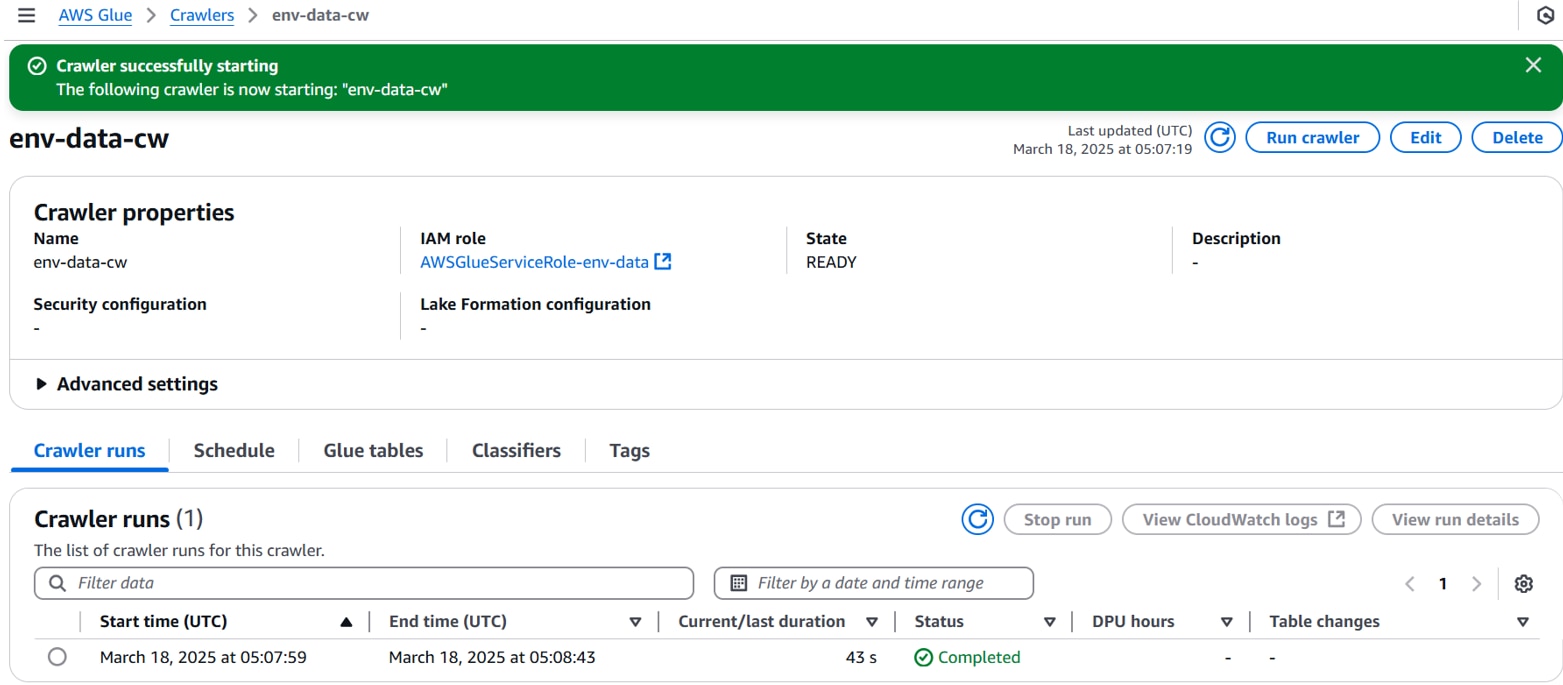
クローラーを実行します。
右上の「Run crawler」をクリックし、Statusが[Completed]になるまで待ちます。
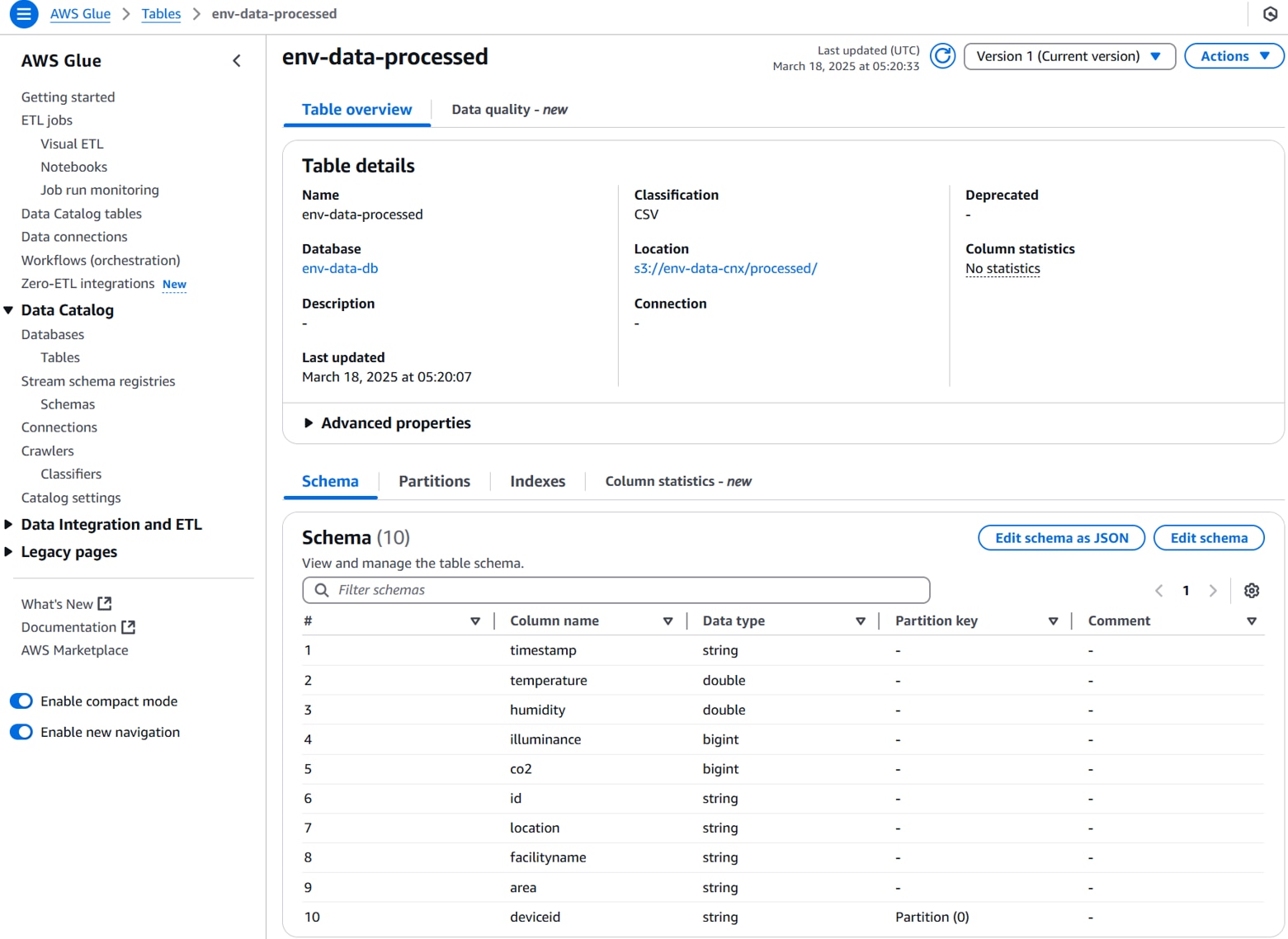
[Data Catalog][Databases][Tables]でテーブルスキーマにクローラーで取得された内容が表示されることを確認します。
・Athenaクエリ結果保存先設定
Athenaコンソールを開き、[クエリエディタ][設定]タブ、クエリの結果と暗号化の設定で「管理」をクリックします。

以下を設定し、「保存」をクリックします。
Location of query result:クエリ結果保存先バケット(例:s3://athena-env-data-cnx/)
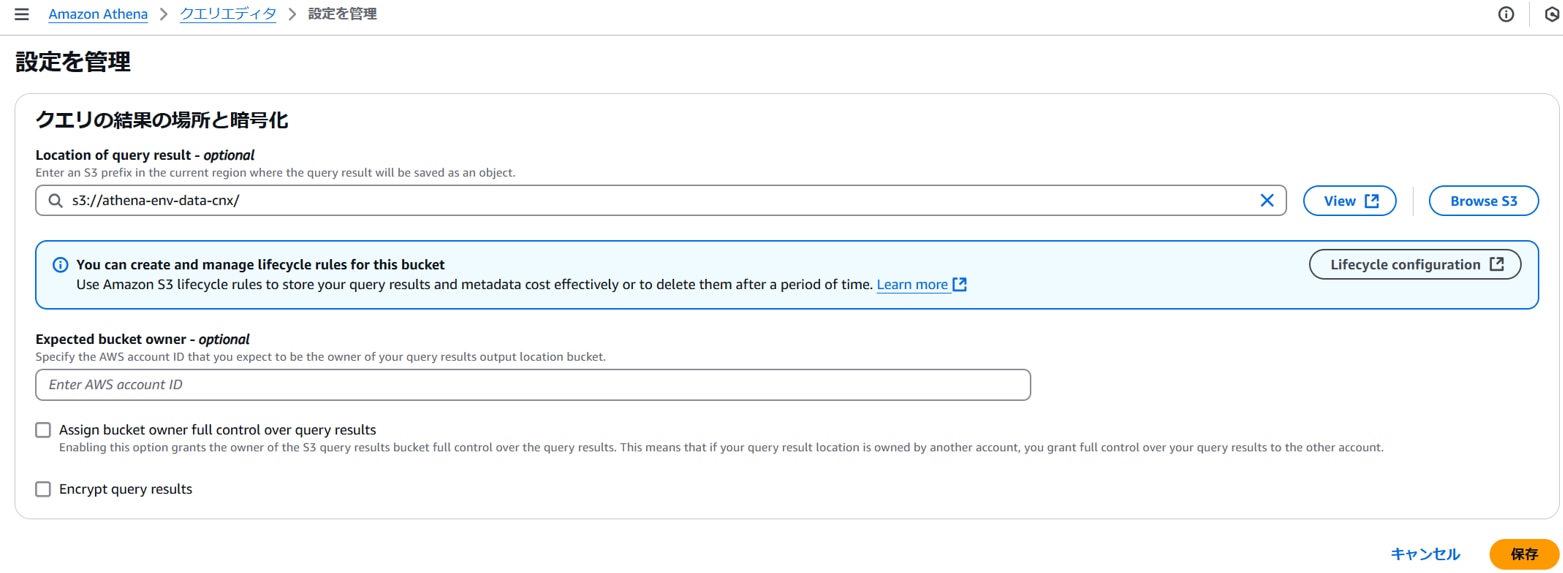
クエリ結果の保存先の場所が設定されます。

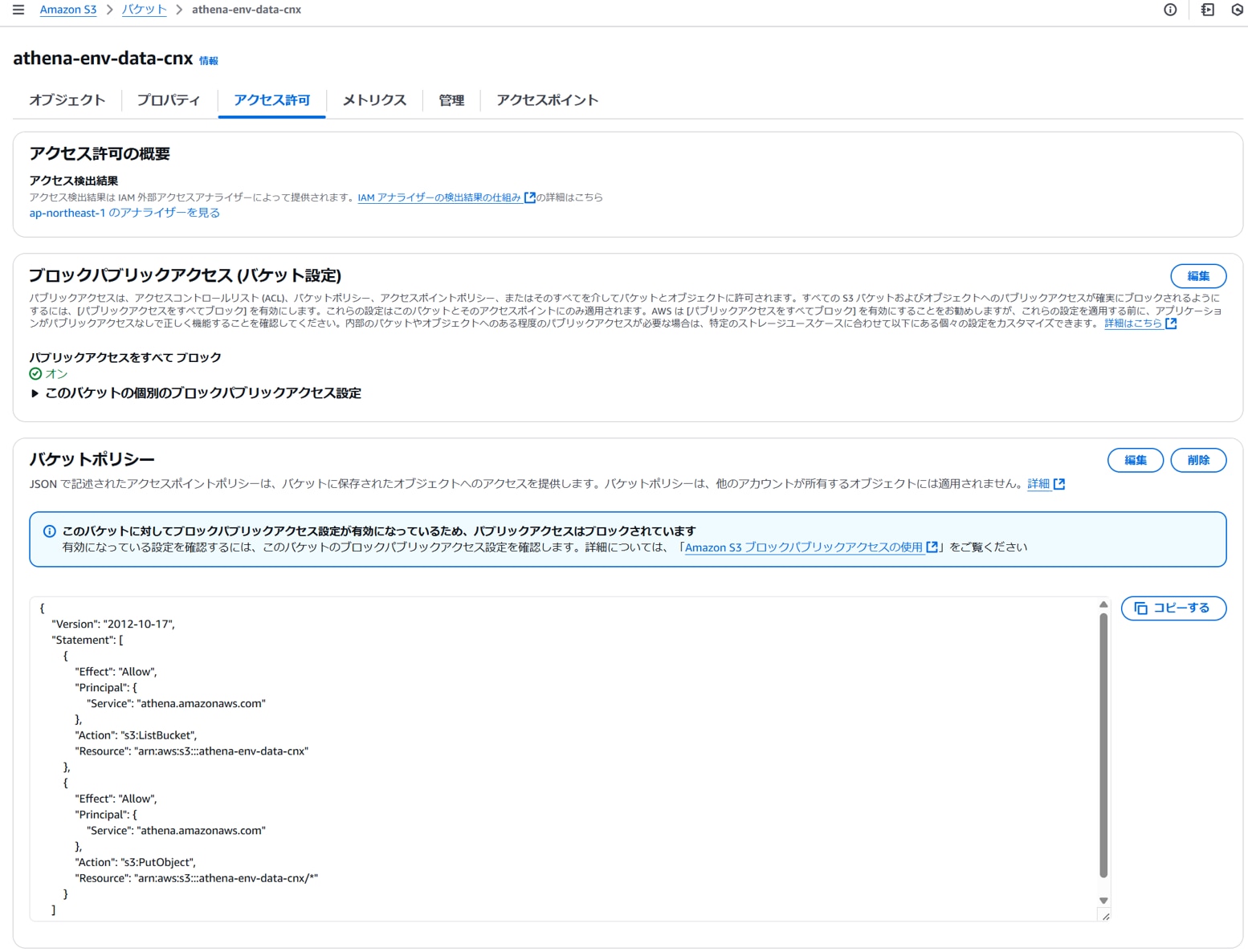
クエリ結果の保存先S3のバケットポリシーにAthenaサービスからのアクセス許可を設定します。
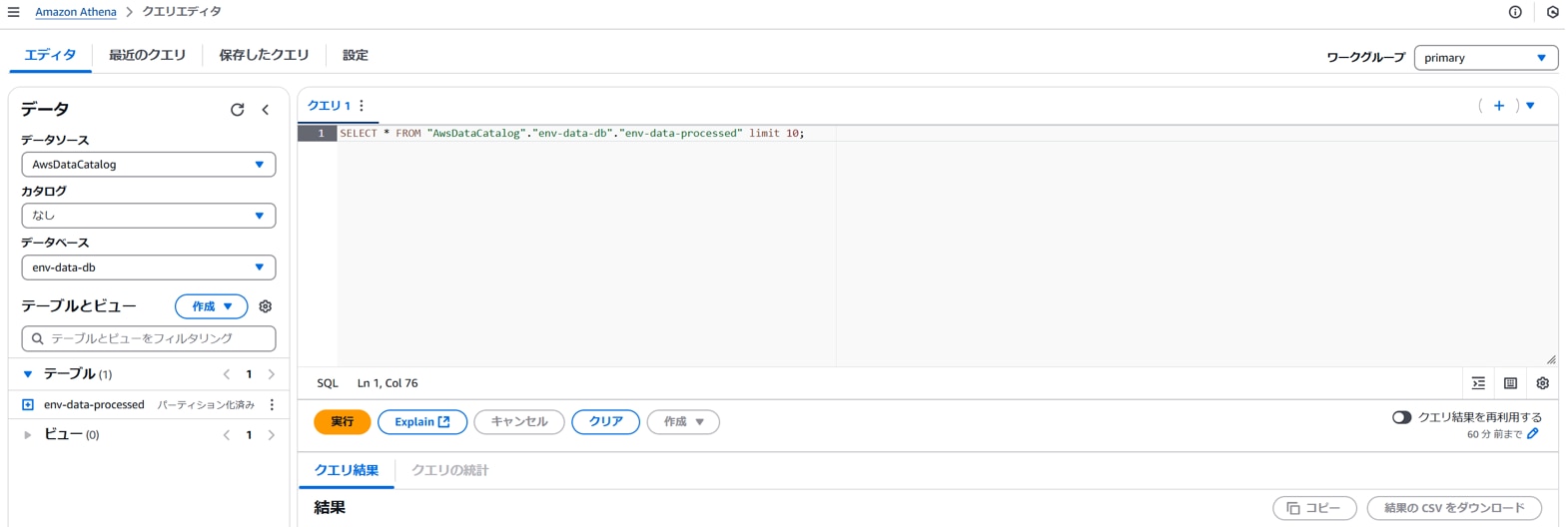
・Athenaクエリ
Athenaコンソールを開き、[クエリエディタ][エディタ]タブ、クエリに以下を入力し「実行」をクリックします。
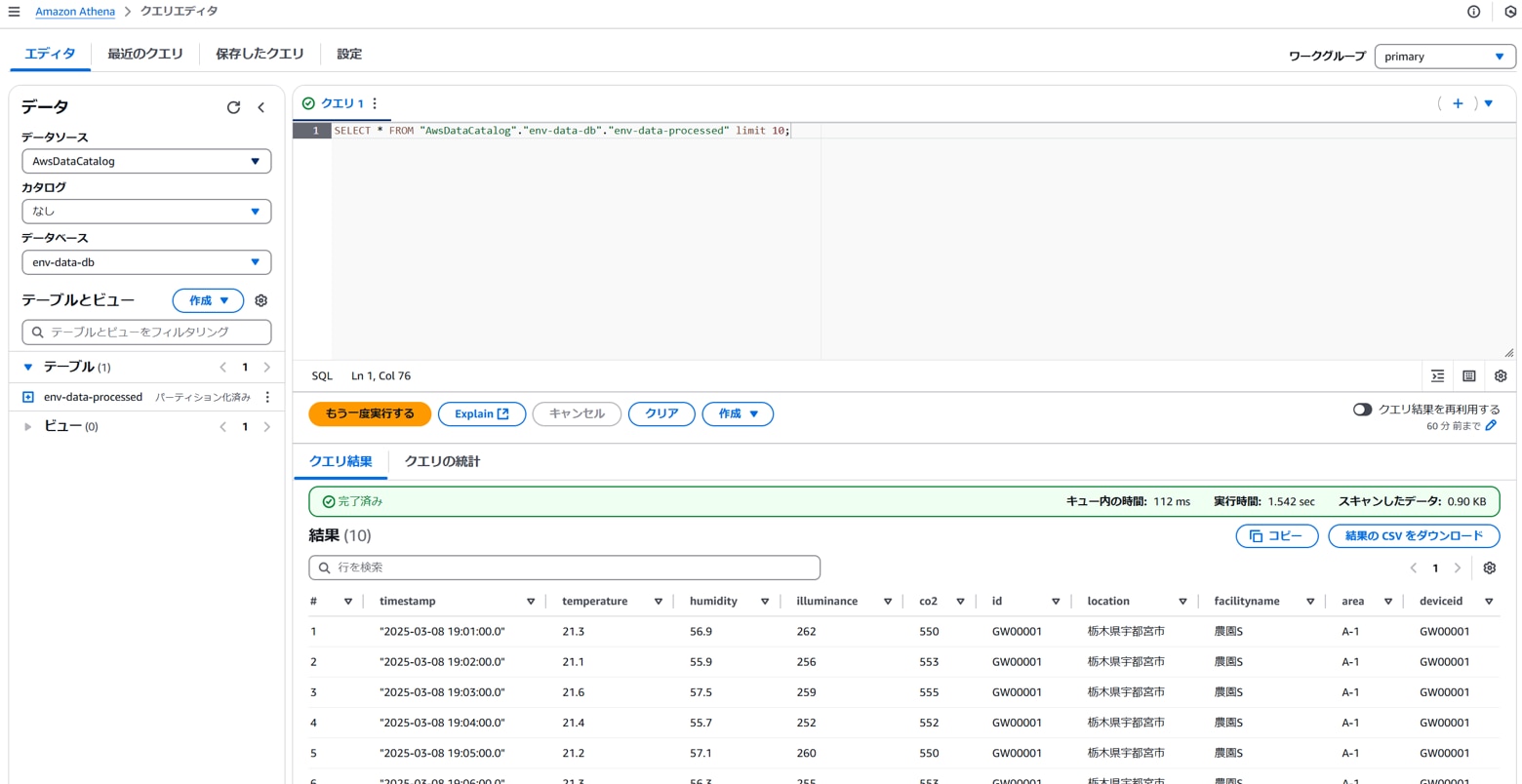
[クエリ結果]に取得したデータが表示されます。
QuickSightの準備
以下のAthenaでのクエリ実行結果をQuickSightで可視化する部分の準備を行います。
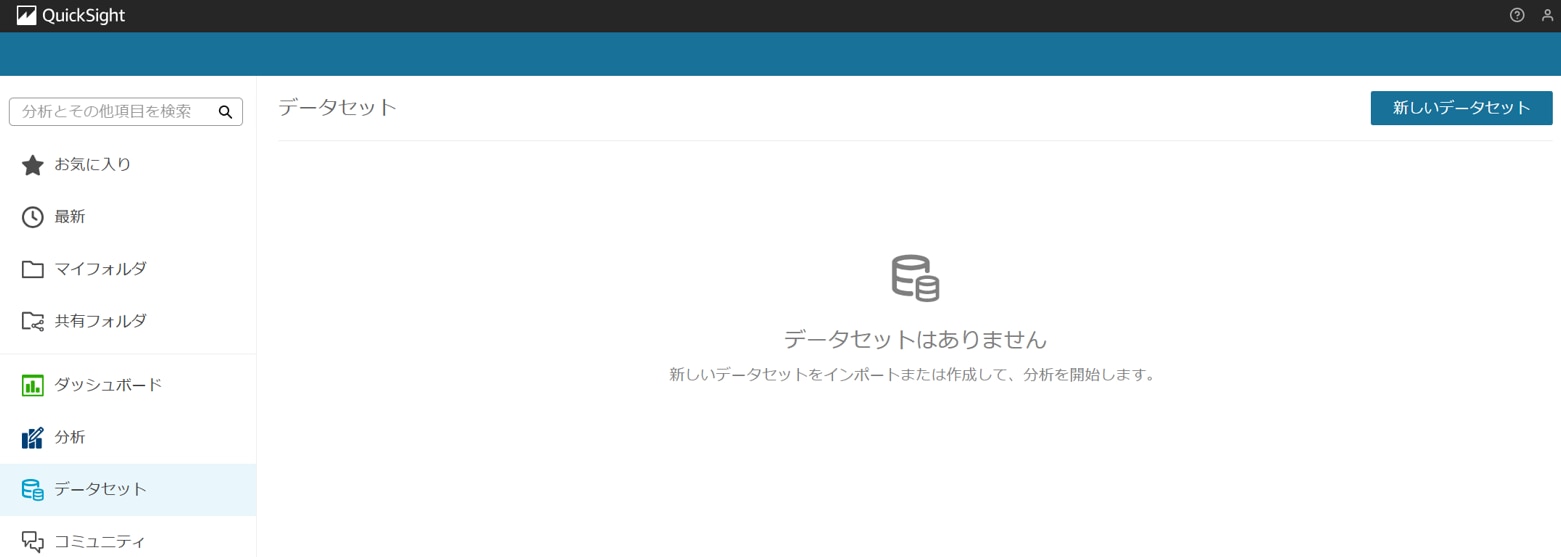
・QuickSightデータセット、分析の作成
QuickSightコンソールを開き、[データセット]「新しいデータセット」をクリックします。
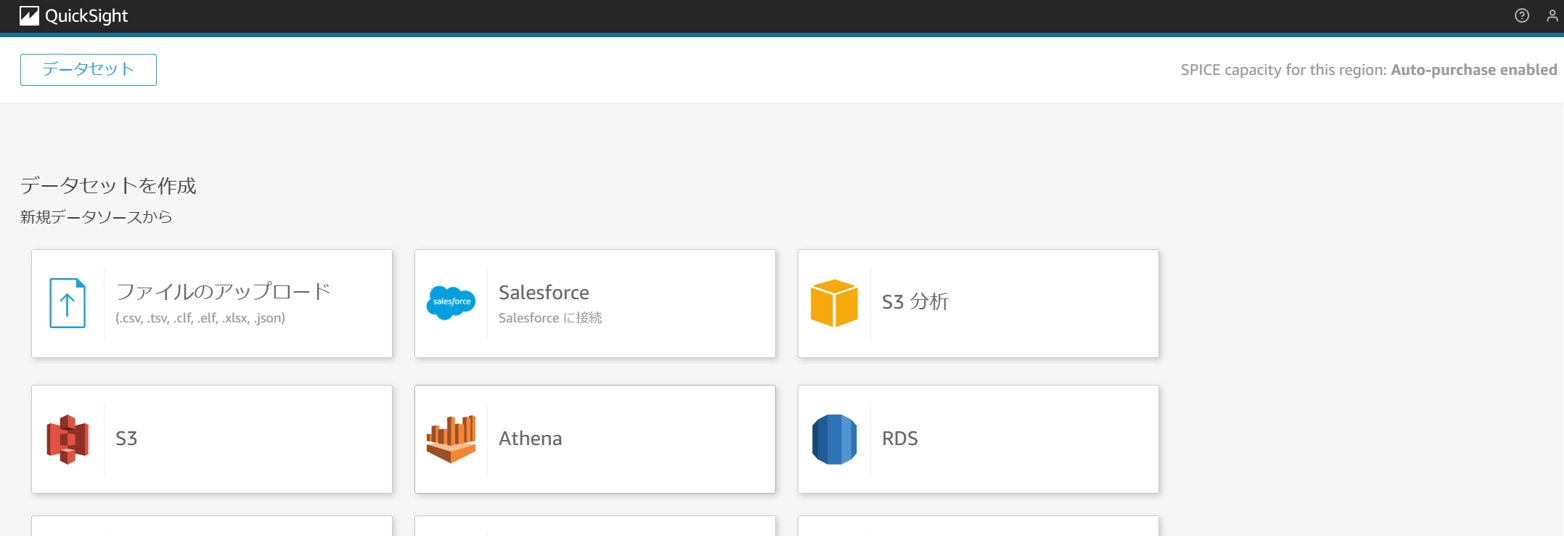
「Athena」をクリックします。
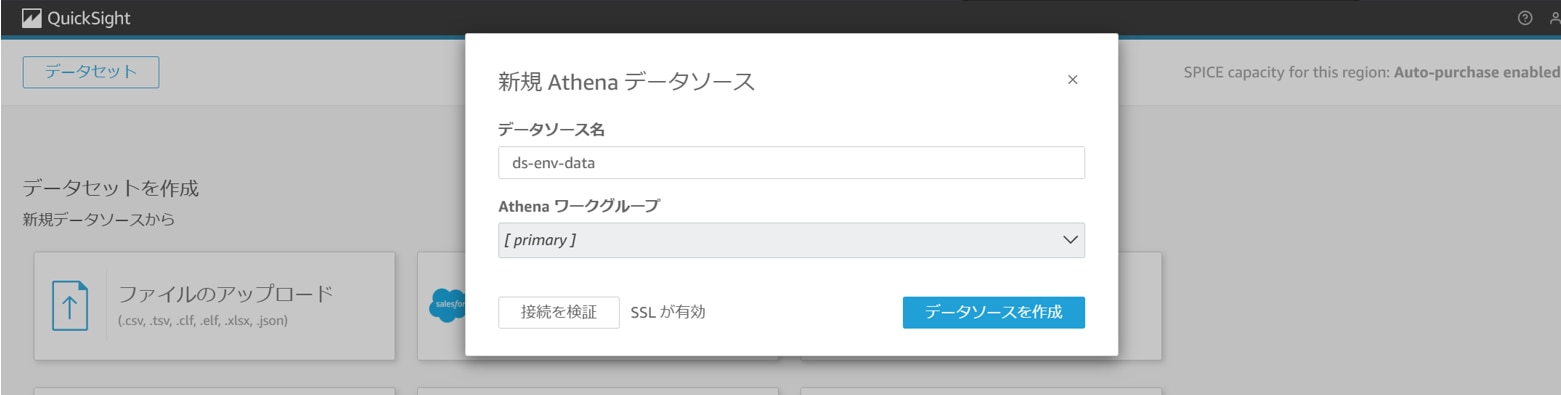
以下を設定し、「接続を検証」をクリックします。
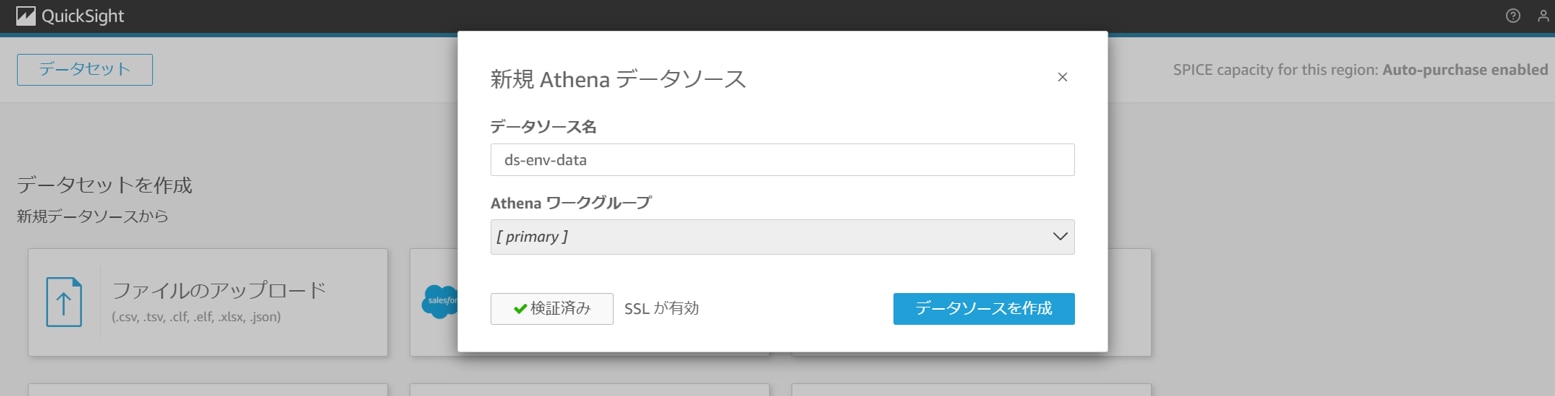
データソース名:任意のデータソース(例:ds-env-data)
[接続済み]となることを確認し、「データソースを作成」をクリックします。
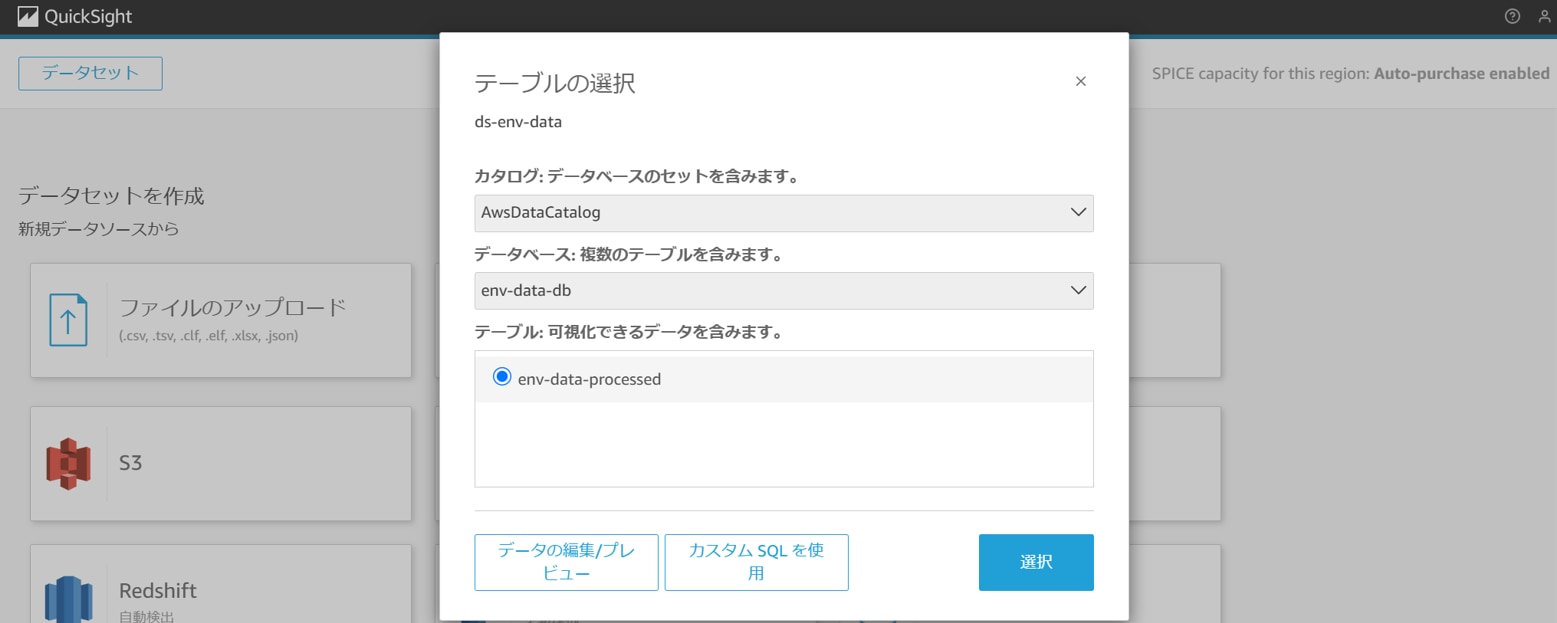
以下を設定し、「選択」をクリックします。
カタログ:AwsDataCatalog
データベース:任意のデータベース(例:env-data-db)
テーブル:任意のテーブル(例:env-data-processed)
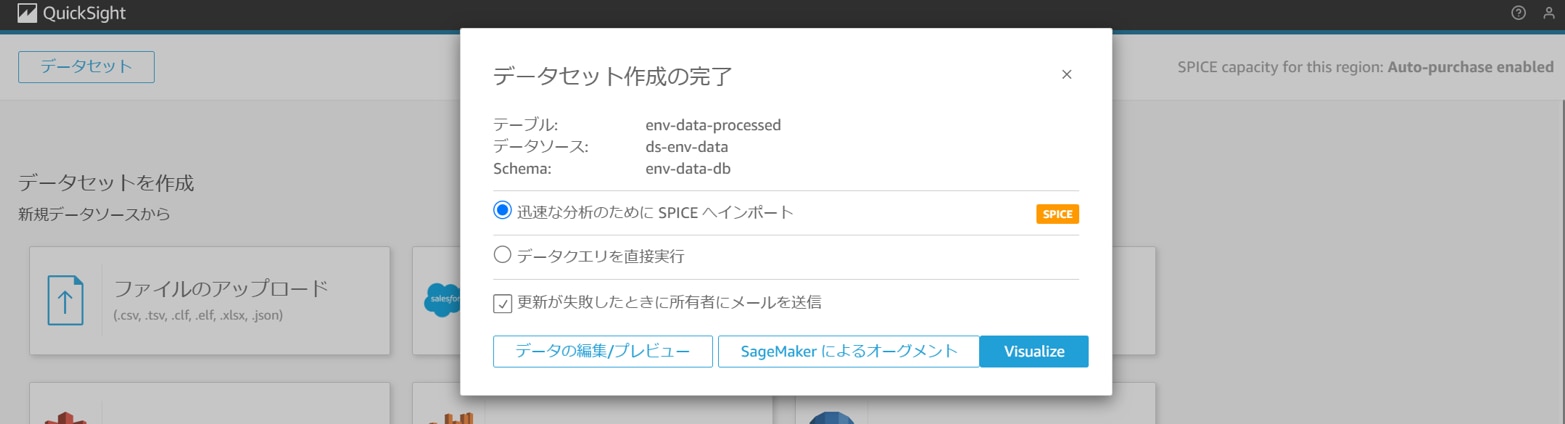
任意の設定を選択し、「Visualize」をクリックします。
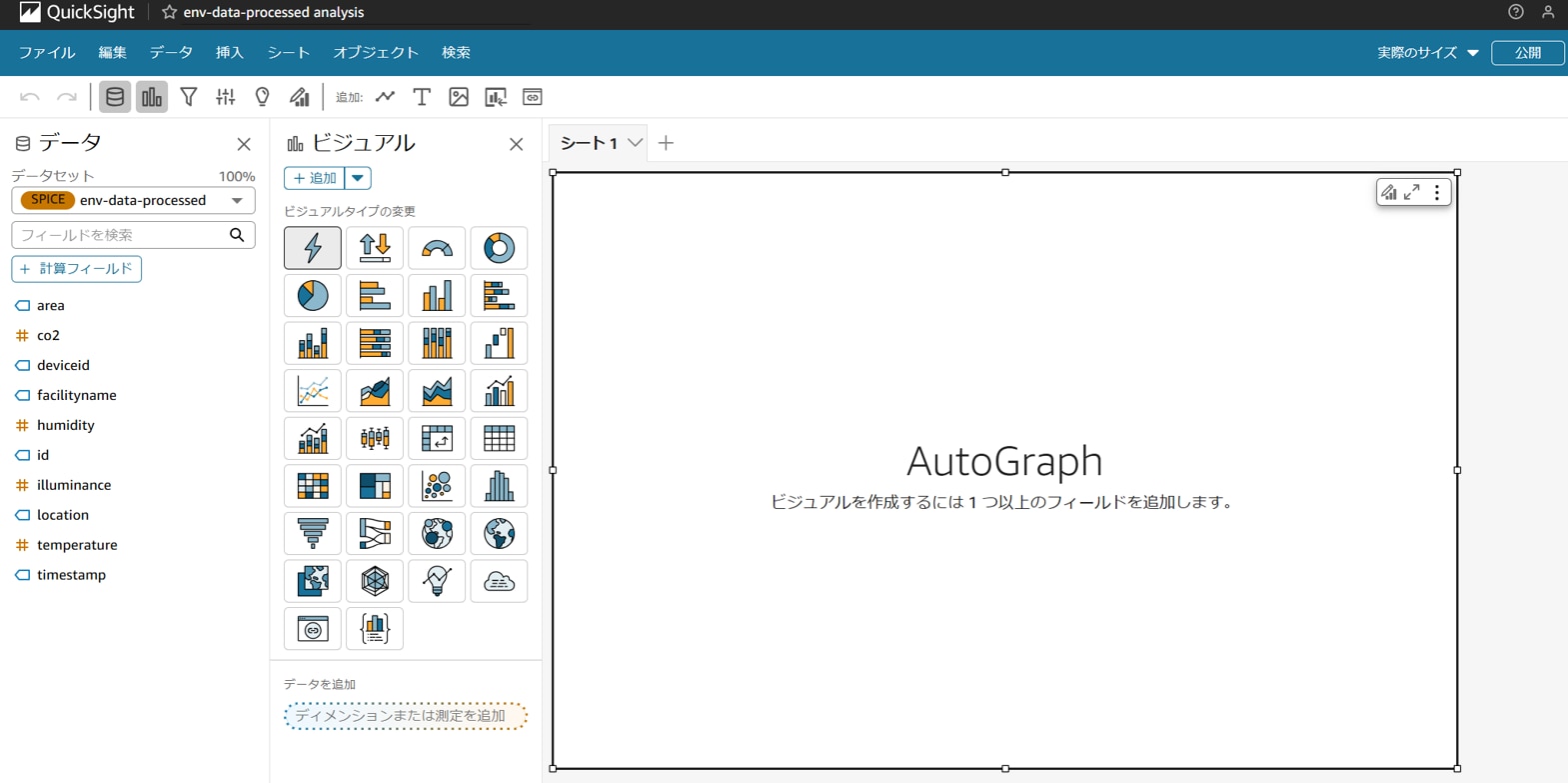
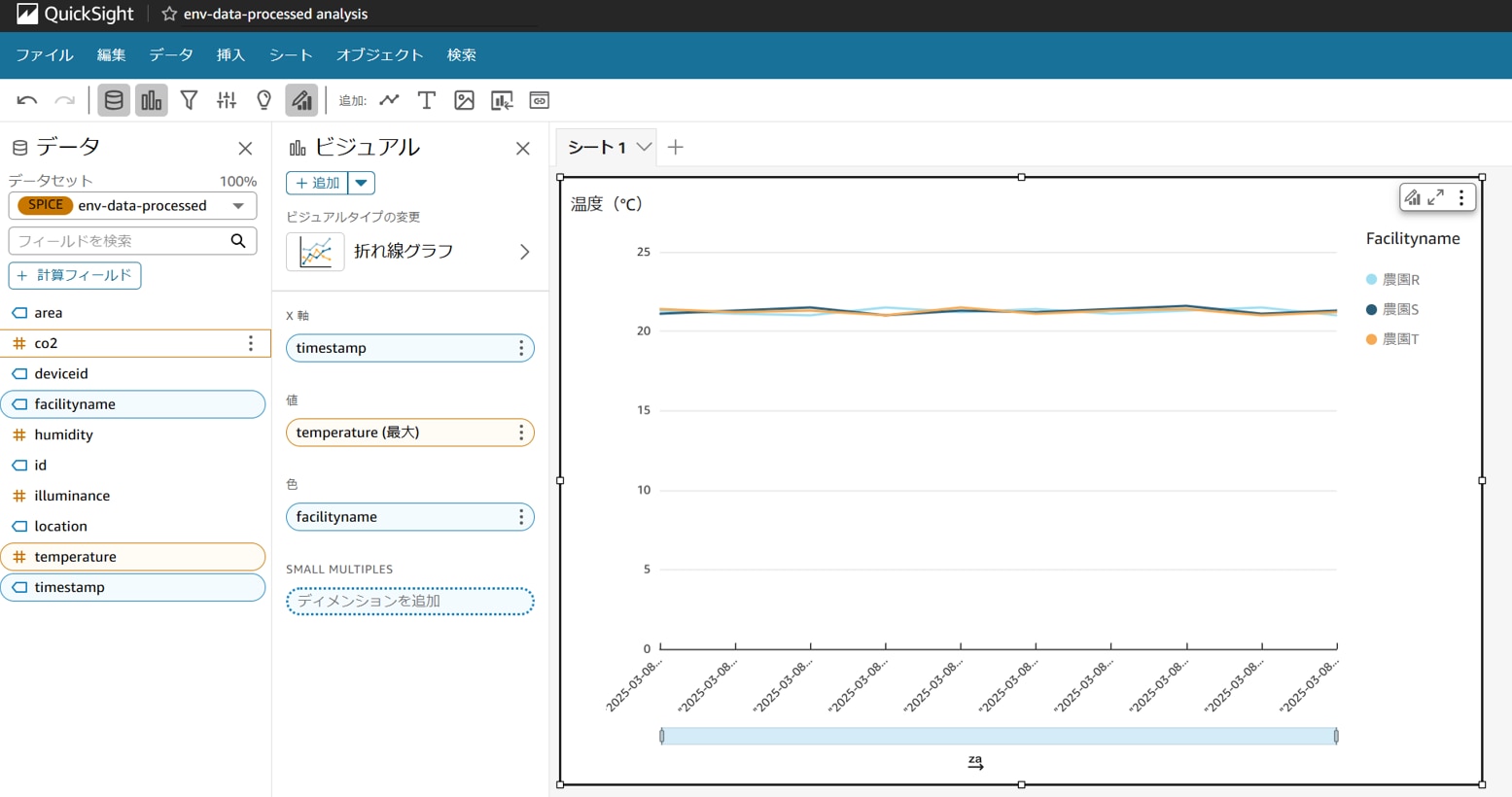
分析作成画面でデータをビジュアル化します。
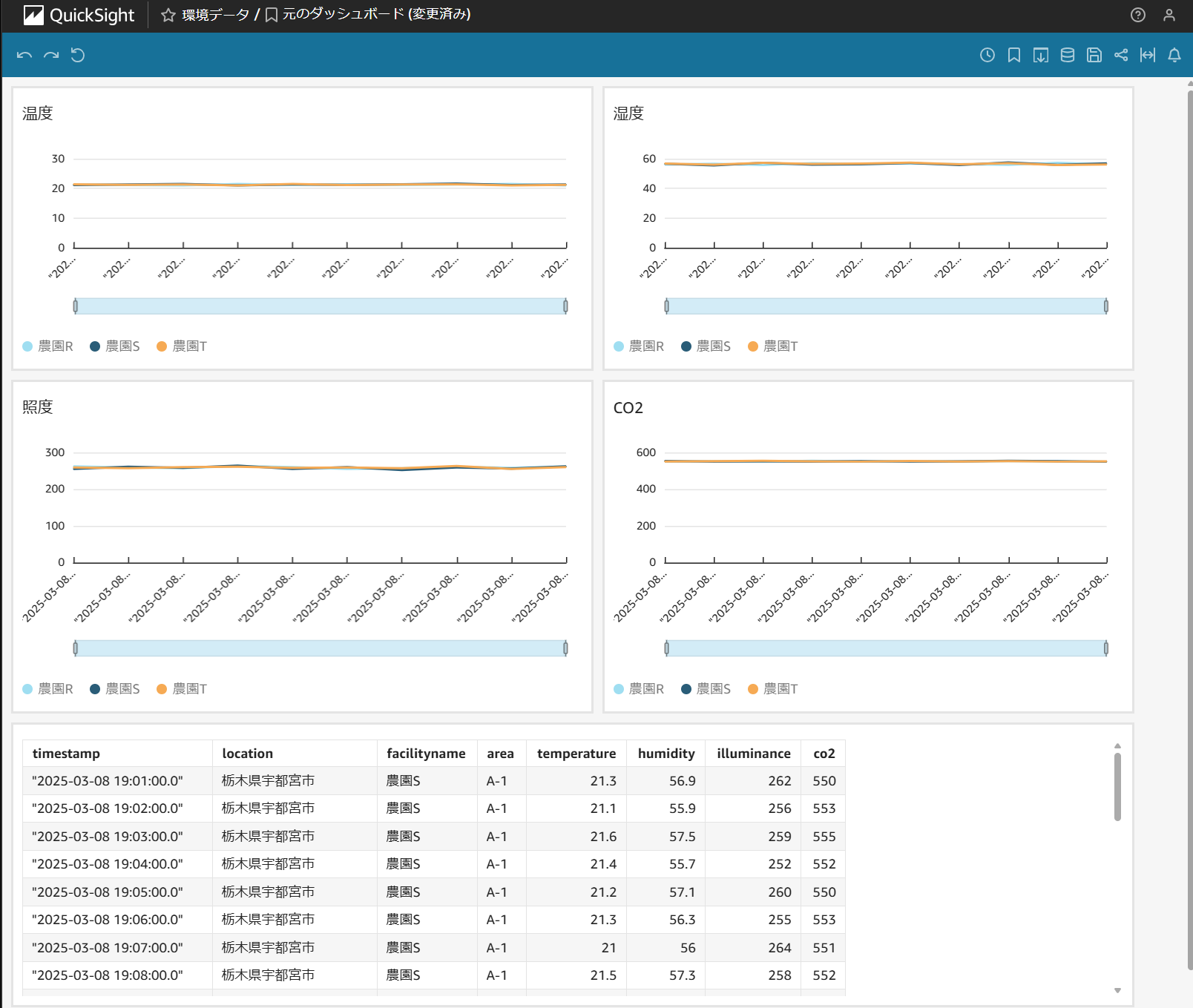
以下は、facilitynameごとの温度推移を折れ線グラフで可視化した例です。
実行確認
以下のようにIoTゲートウェイから受信した環境データがS3(raw)に生データ(JSON)として作成された後、イベント通知によって加工されたデータが作成され、Athenaが実行したクエリ結果がQuickSightで可視化できることを確認します。

・イベントの実行
以下のようにIoTゲートウェイから受信した環境データがS3(raw)に生データ(JSON)として作成されます。
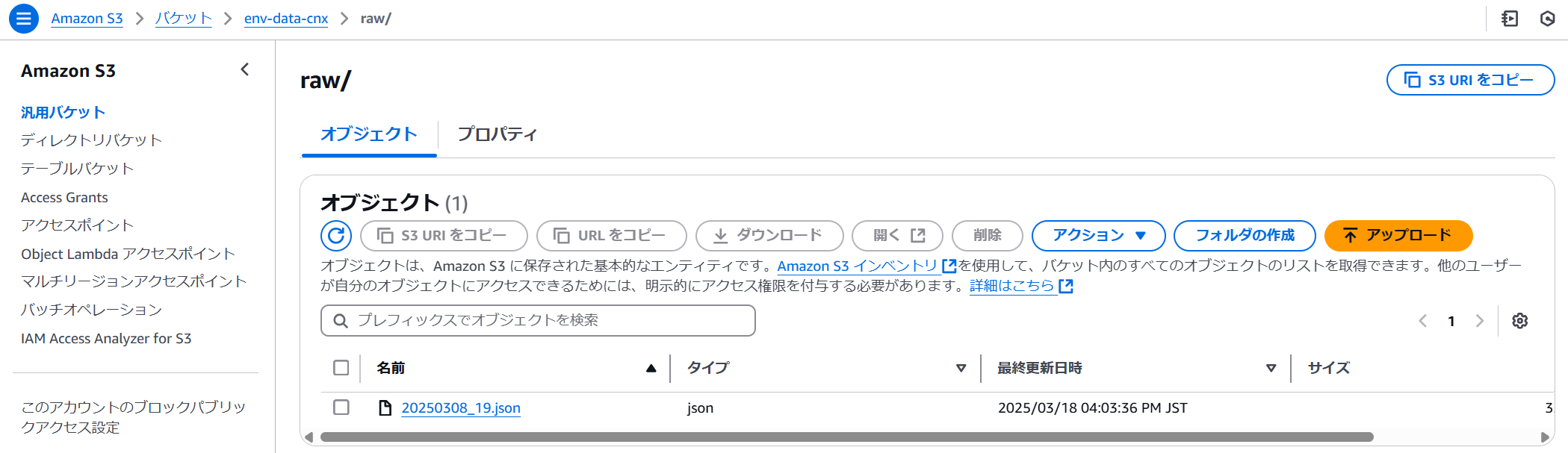
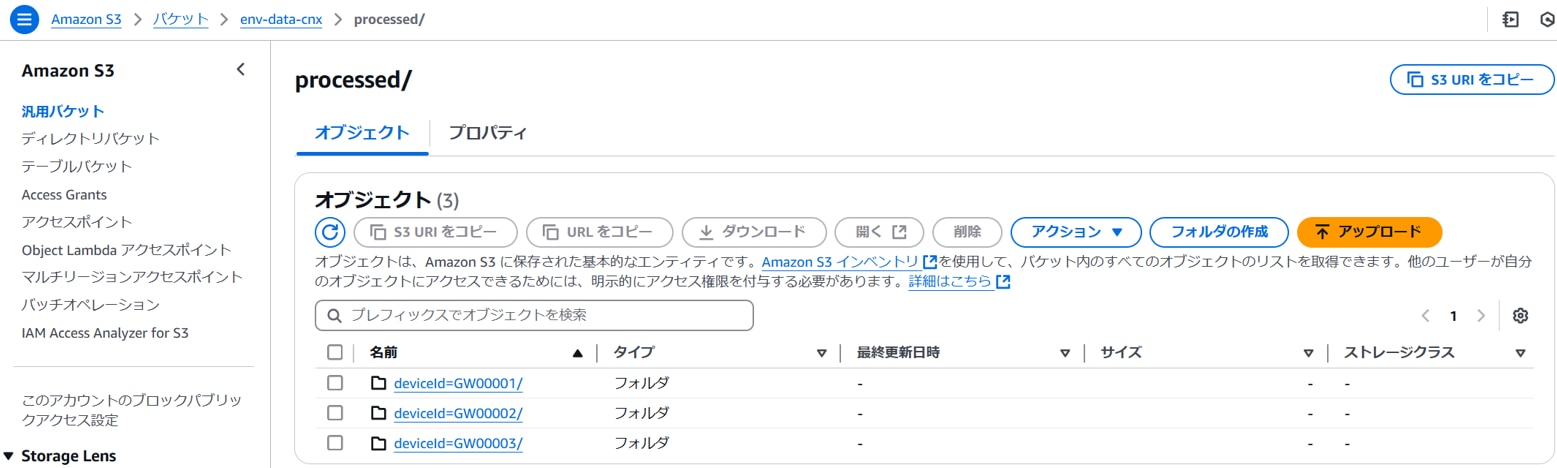
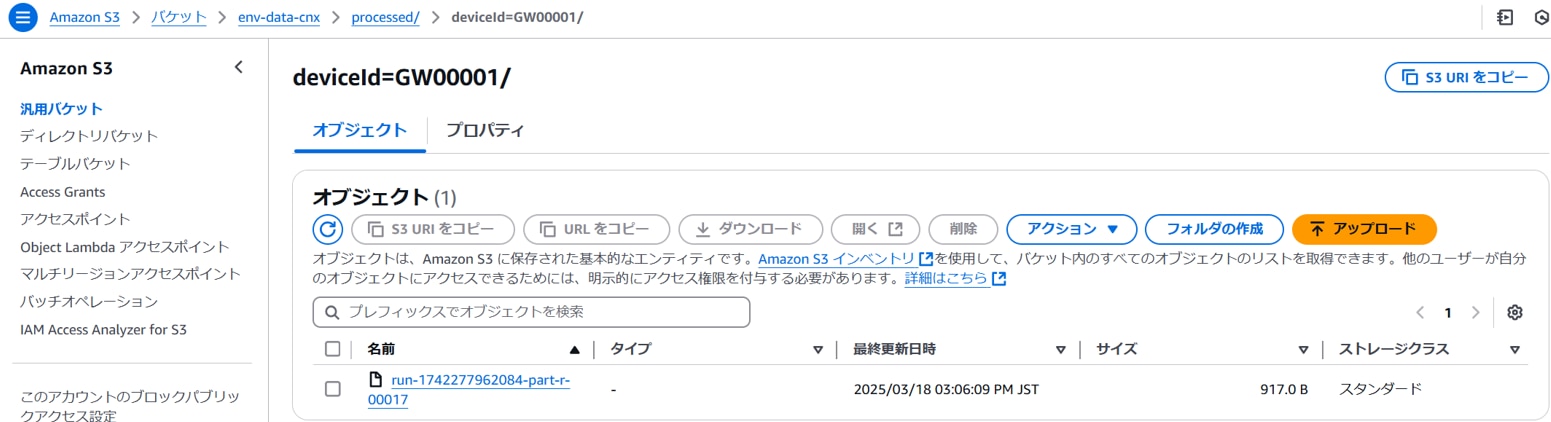
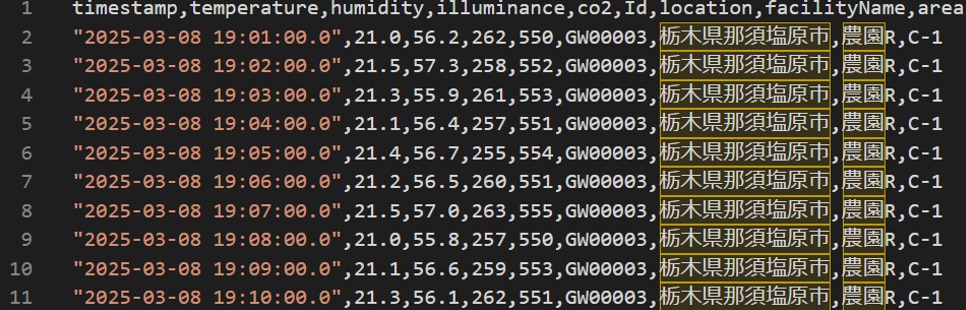
S3(raw)に生データ(JSON)が作成されるとイベント通知によってGlue Job(ETL)が実行され加工されたデータがS3(processed)に作成ます。以下が加工データ(一部抜粋)です。※Glue Job(ETL)のTargetパーティション設定に従ってdeviceid毎にフォルダが作成され、deviceid毎にCSVファイルが作成されています。
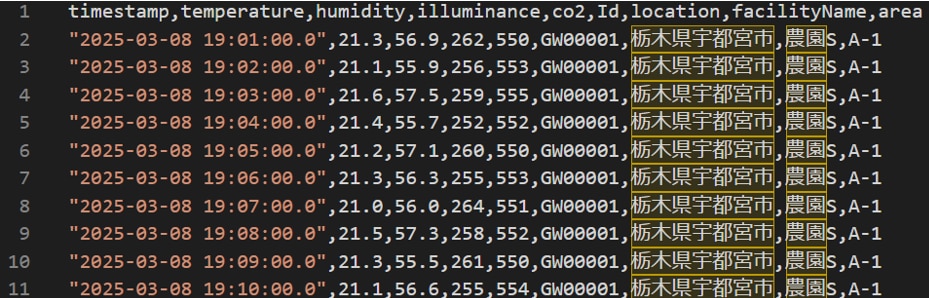
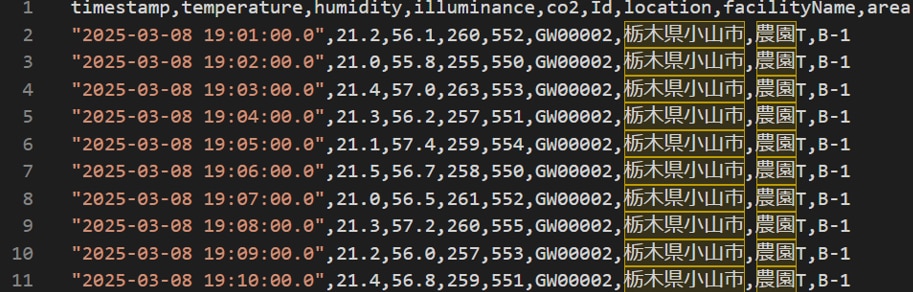
・QuickSightダッシュボードでデータ確認
加工データに対してAthenaが実行したクエリ結果がQuickSightで可視化できることを確認します。以下が加工データを可視化したダッシュボード例です。
まとめ
前編ではデータ加工の準備と、そのデータ加工をイベントで起動するためのセットアップ方法を解説しました。そして後編では、Athenaでのクエリ結果をQuickSightで可視化するための準備と動作確認の手順をご紹介しました。
今回の環境構築では、Glueデータカタログやクローラーの仕組みをしっかりと理解することが重要だと感じました。構築を進める中で、私自身もこれらの理解をさらに深められたと思います。
ただし、各サービス間のアクセス許可や権限設定は、やはりつまずきやすいポイントですね。
この部分については、次回のテックブログでさらに詳しく触れられたらと考えています。
▼オススメ関連記事
「サーバーレスのイベント駆動型ワークフローを作成!AWS Glue と Amazon EventBridgeでやってみた【前編】」
「工事不要でIoTをお手軽導入!「EDConnectワイヤレス」とは? 」
「IoTに必須のIoTセンサの種類と特長、活用事例を解説 」
▼EDconnectワイヤレスの資料ダウンロードはこちらから