サーバーレスのイベント駆動型ワークフローを作成! AWS Glue と Amazon EventBridgeでやってみた【前編】 (1)
ようこそ、IoTに関する技術的な内容を紹介するコネクシオのテックブログへ!
コネクシオでは、お客様にクラウド環境とセットでIoTソリューションを数多くご提供しており、その中で、IoTゲートウェイが収集した環境データを、より効果的に可視化・分析するために、 クラウド側でデータを加工することがあります。
IoTゲートウェイから送信されるデータをそのままクラウドで扱いやすく加工することも可能ですが、ゲートウェイで保持していないデータを付加したり、ユーザーの可視化・分析基盤に適した形式に調整したりする場合、クラウド側でのデータ加工が必要となります。
今回は、 AWS Glue と Amazon EventBridge を使用して取り込んで処理するサーバーレスのイベント駆動型ワークフローを作成して、Amazon QuickSightで可視化までを行う例を前編後編に分け、じっくりとご紹介します。
前編となる今回を一読いただき、IoTデータ活用を始めたり、見直すきっかけになれば幸いです!
▼オススメ関連記事
「 工事不要でIoTをお手軽導入!「EDConnectワイヤレス」とは?」
「 IoTに必須のIoTセンサの種類と特長、活用事例を解説 」
「 サーバーレスのイベント駆動型ワークフローを作成! AWS Glue と Amazon EventBridgeでやってみた【後編】」
はじめに
前編ではデータ加工の準備と、そのデータ加工をイベントで起動するためのセットアップ方法を解説します。
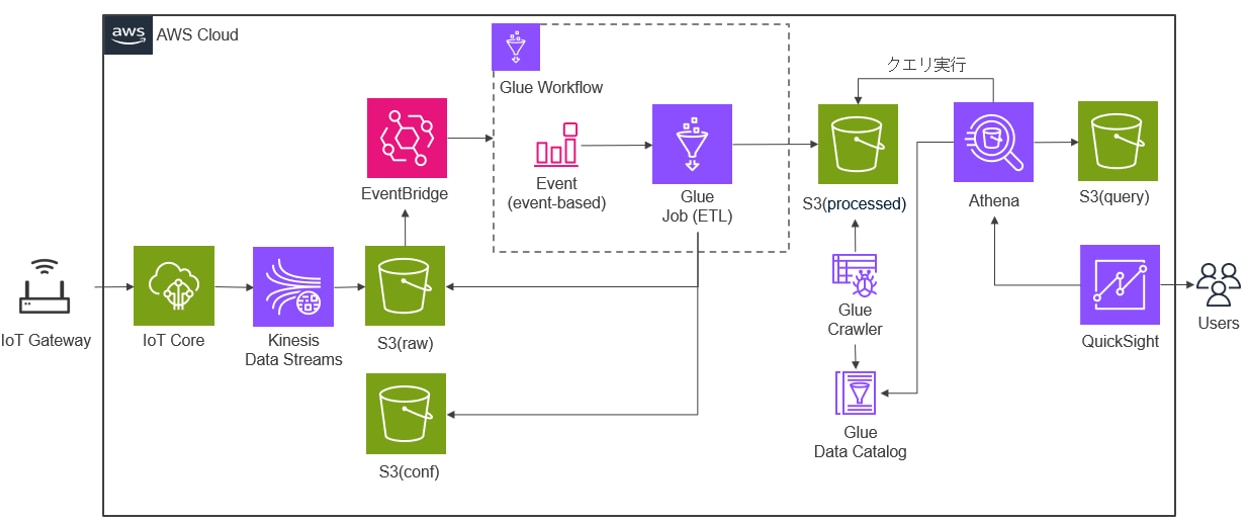
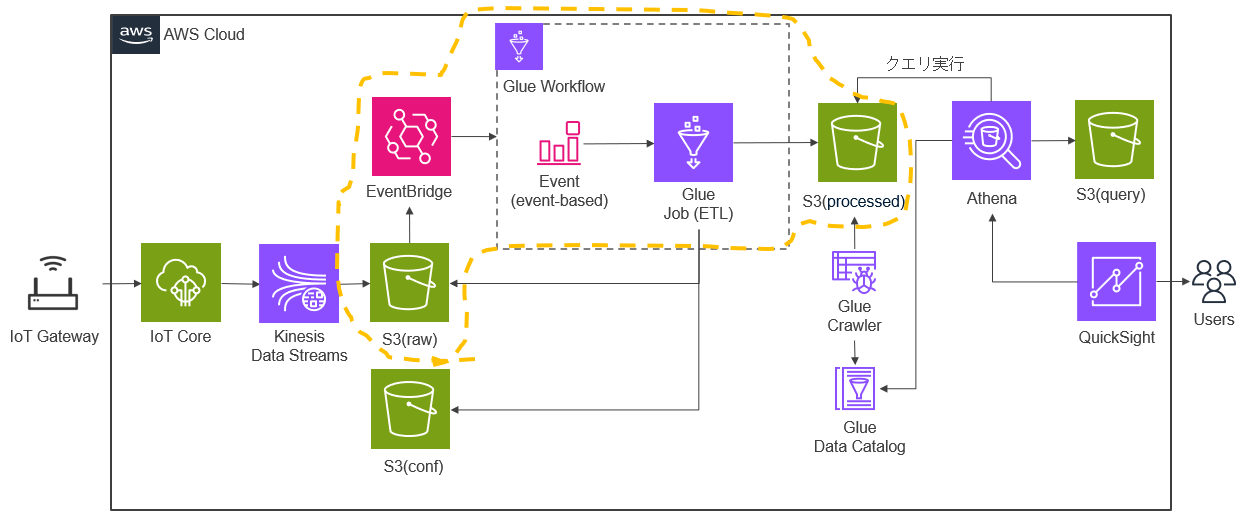
今回は以下のような構成でAWSのリソースを準備し、IoTゲートウェイから収集した環境データを AWS Glue と Amazon EventBridge を使用してデータを加工して取り込み、Athenaでのクエリ結果をQuickSightで可視化します。
前編ではデータ加工の準備と、そのデータ加工をイベントで起動するための準備を行います。
加工データ
今回行うデータの加工は以下のような内容になります。IoTゲートウェイから受信した内容に、クラウド側で持つGW設定ファイルの内容からdeviceIdに紐づく設備情報を付加してCSVファイルを作成します。

前提条件
・IoT Coreによるデバイス認証、モノの登録
・IoT Coreで取得した情報をKinesis Data FirehoseでまとめてS3に保存するための設定
・Sバケット、フォルダ作成および、必要ファイルの格納
・QuickSightのアカウント登録
・Athenaのクエリ結果の場所の設定
・IoTゲートウェイが各種センサーから収集した環境データをIoT Coreへ送信するための設定
また、今回は各サービスについての説明については割愛しています。
やってみよう
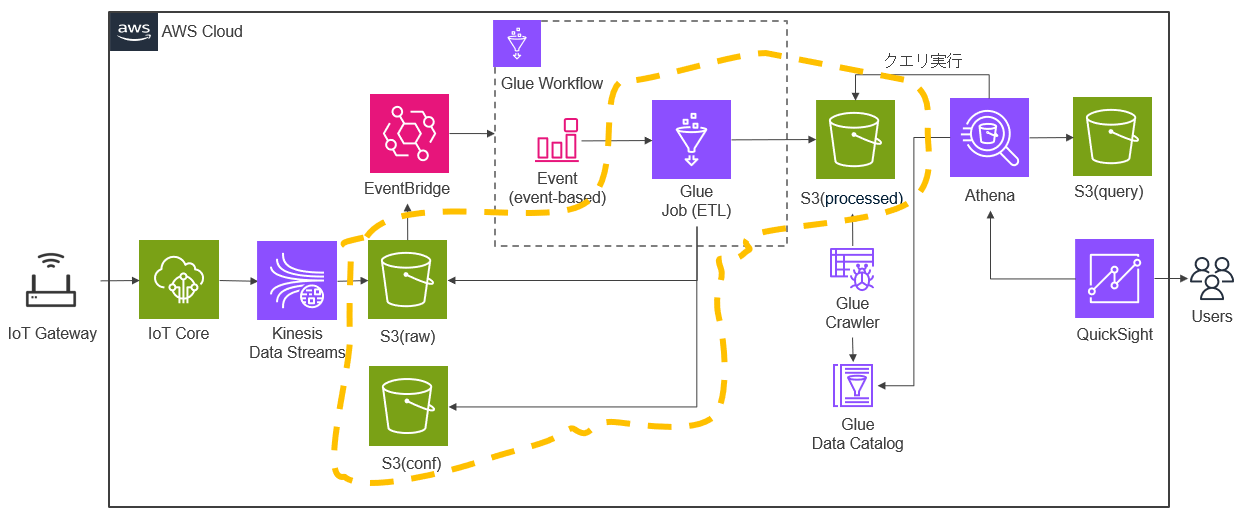
データ加工の準備
以下のデータ加工部分の準備を行います。S3(raw)の生データ(JSON)と、S3(conf)のGW設定ファイル(gateways.json)の内容からS3(processed)に加工データ(CSV)を作成するGlue Job(ETL)を作成します。
・Glue Job(ETL)の作成
AWS Glueコンソールを開き、[ETL jobs]、[Visual ETL]、「Visual ETL」をクリックします。
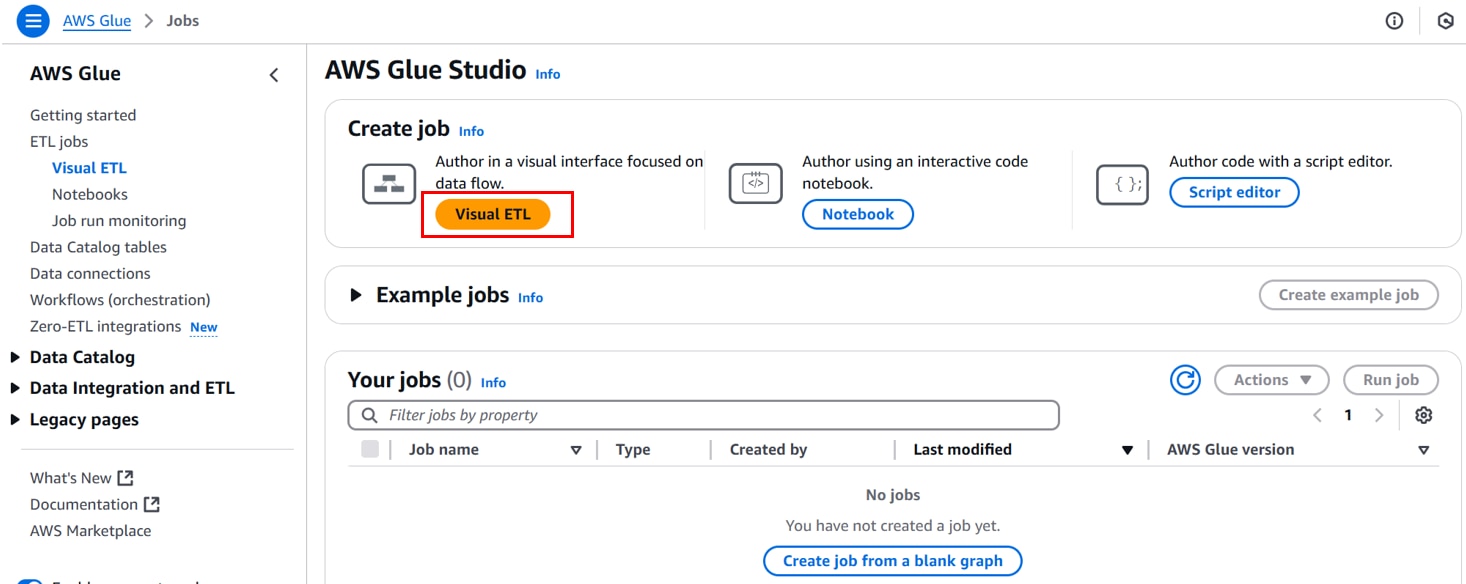
任意のジョブ名を入力し、「+」をクリックします。
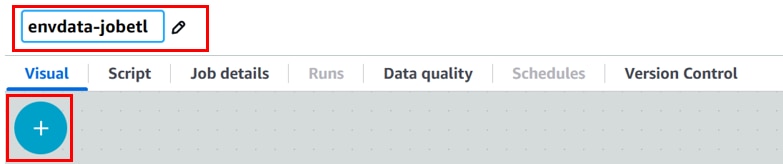
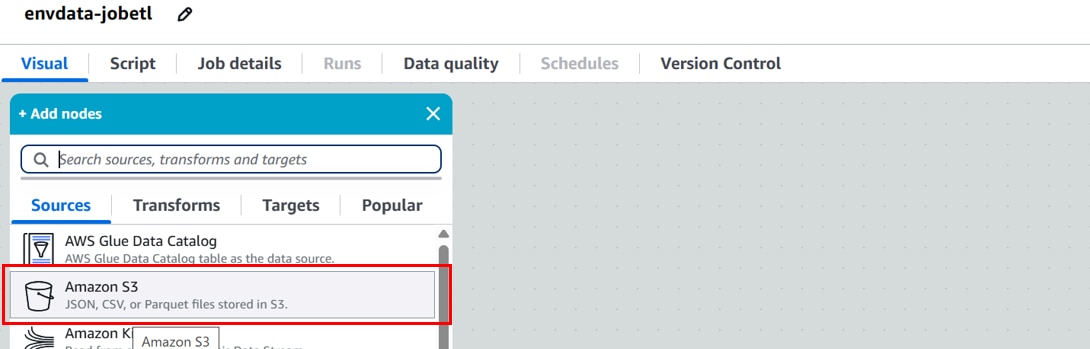
[Add nodes][Sources]、「Amazon S3」をクリックします。
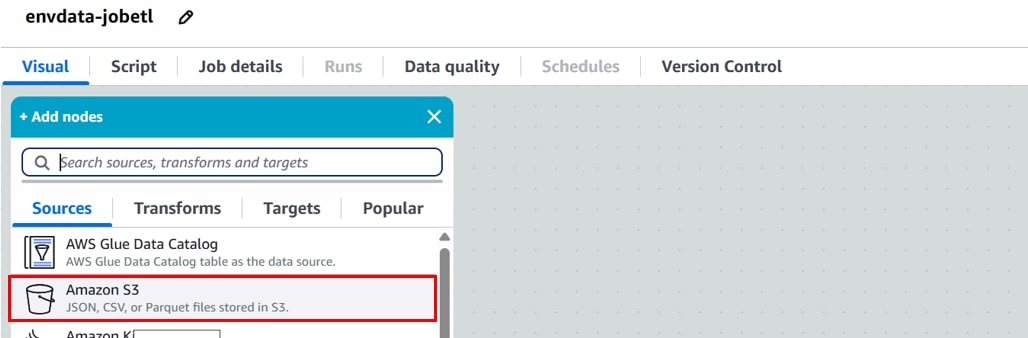
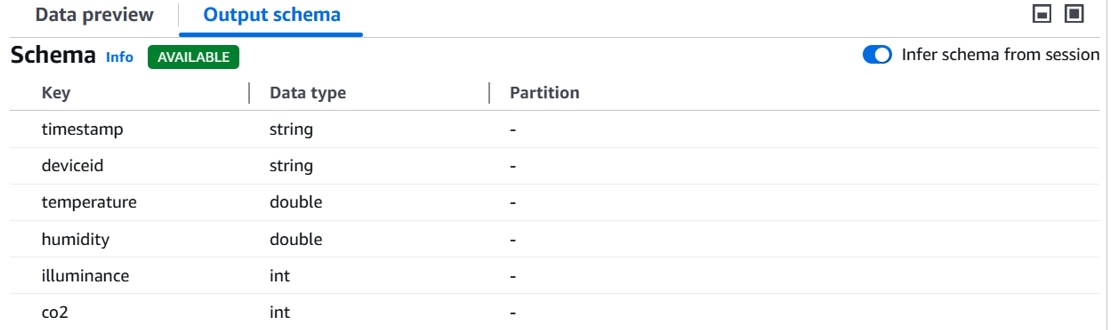
[Data source properties]に以下の設定を行い、「Infer schema 」をクリックします。
Name:データソース名。(例:raw)
S3 URL:生データを格納するフォルダ。(例:s3://env-data-cnx/raw/)
Data format:データフォーマット。(例:JSON) 
画面下部[Output schema]にスキーマ定義が表示されます。
[Add nodes][Sources]、「Amazon S3」をクリックします。
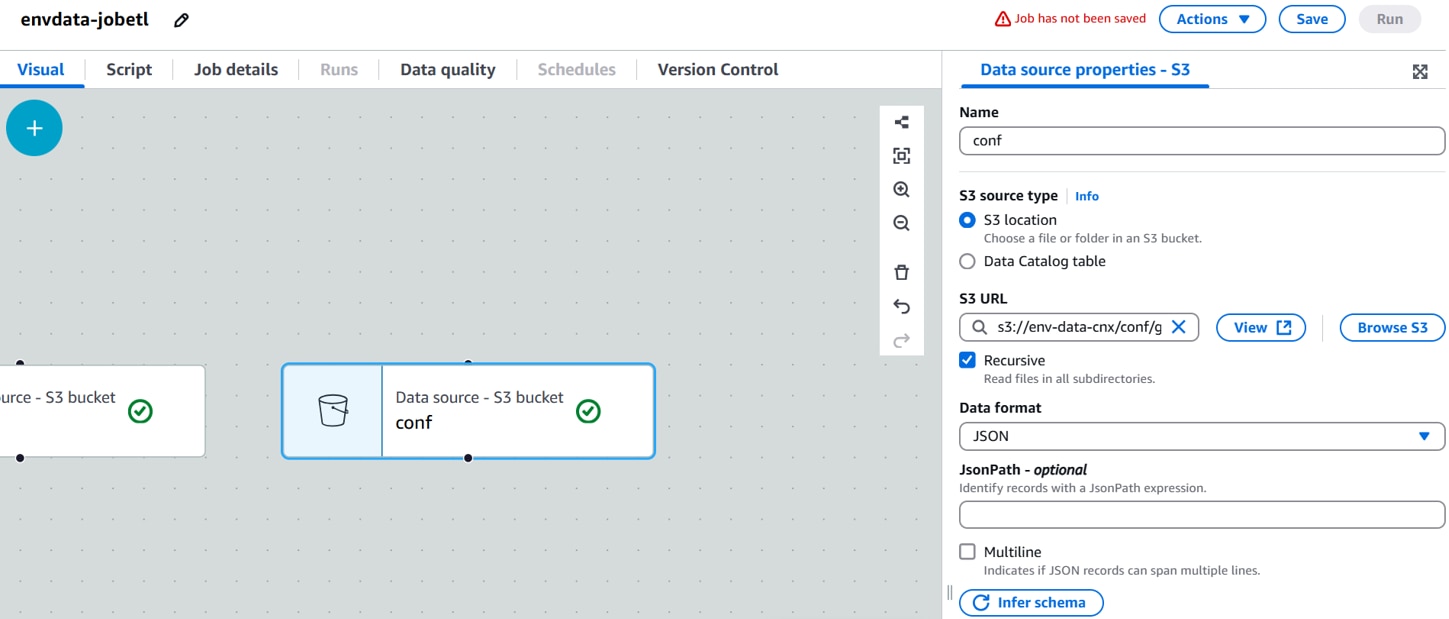
Data source properties]に以下の設定を行い、 「Infer schema 」をクリックします。
Name:データソース名。(例:conf)
S3 URL:生データを格納するフォルダ。(例:s3://env-data-cnx/conf/gateways.json)
Data format:データフォーマット。(例:JSON)
画面下部 [Output schema]にスキーマ定義が表示されます。

[raw]ノードを選択した状態で、「+」、[Transforms]「Join」をクリックします。
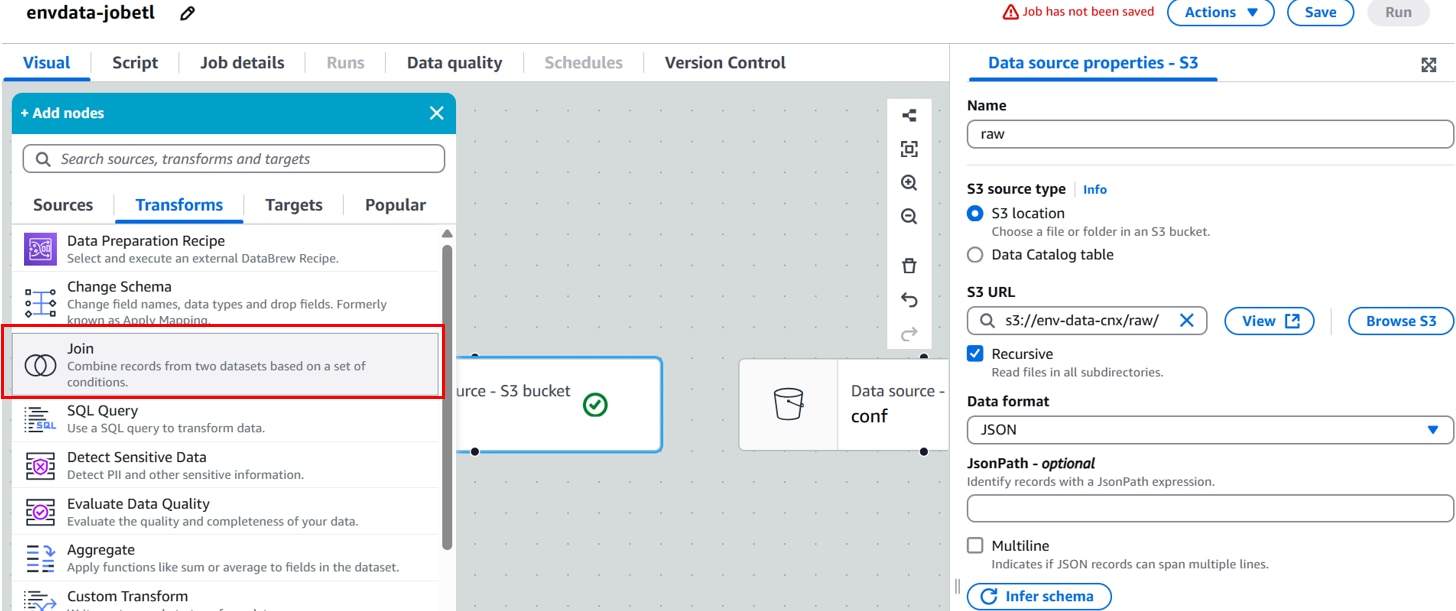
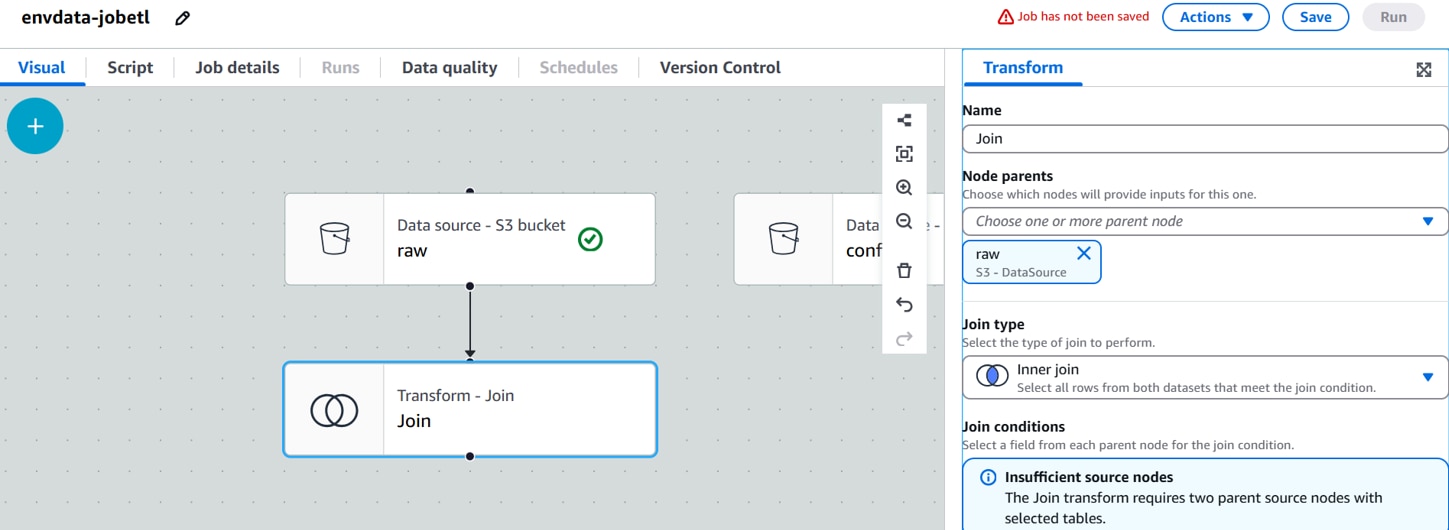
[Transform]を以下に設定します。
Name:Transform名。(例:Join)
Node parents:親ノード。(例:rawデータソースノード, confデータソースノード)
Join type:結合タイプ。(例:Left join)
Join conditions:結合条件。(例:deviceid(raw)=id(conf))
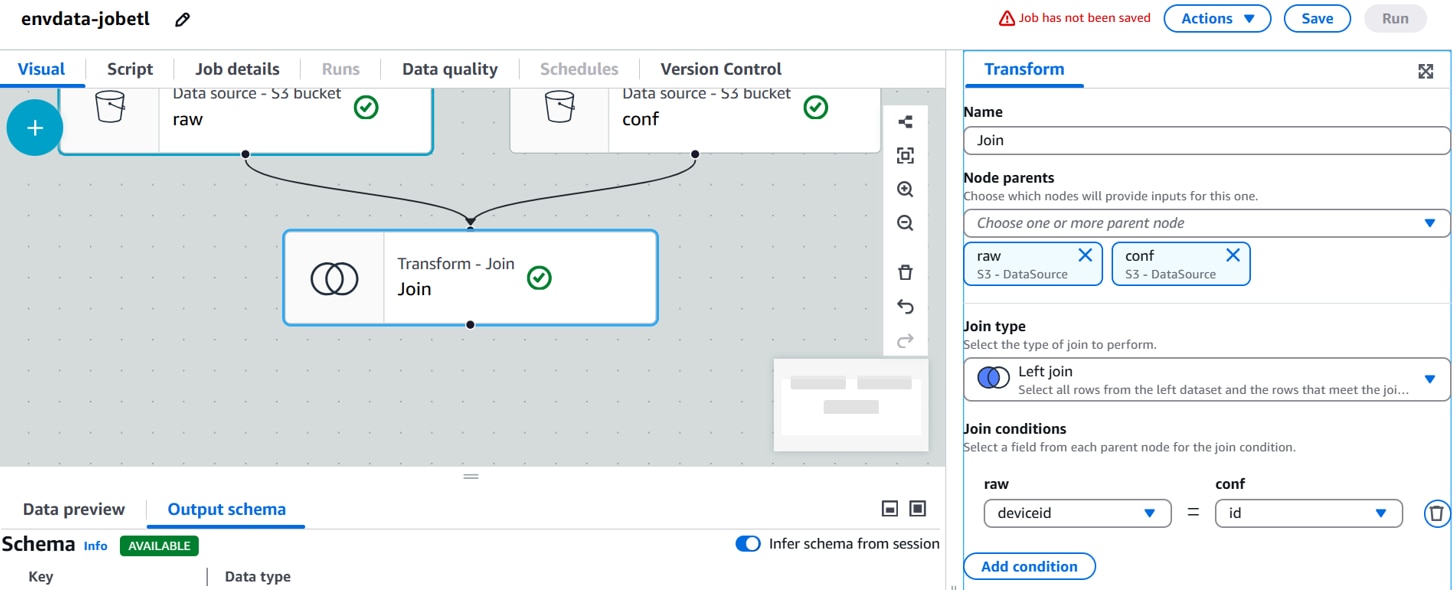
画面下部 [Output schema]にスキーマ定義が表示されます。
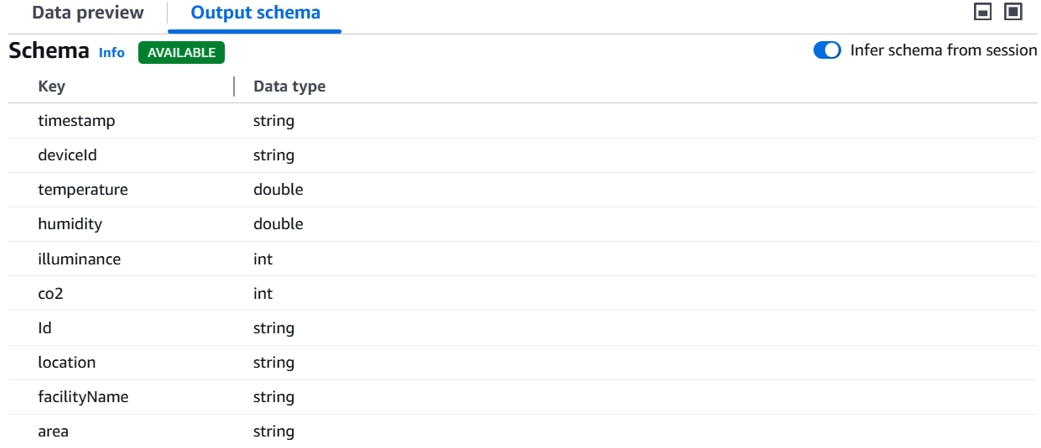
[Join]ノードを選択した状態で、「+」、[Transforms]「Change Schema」をクリックします。
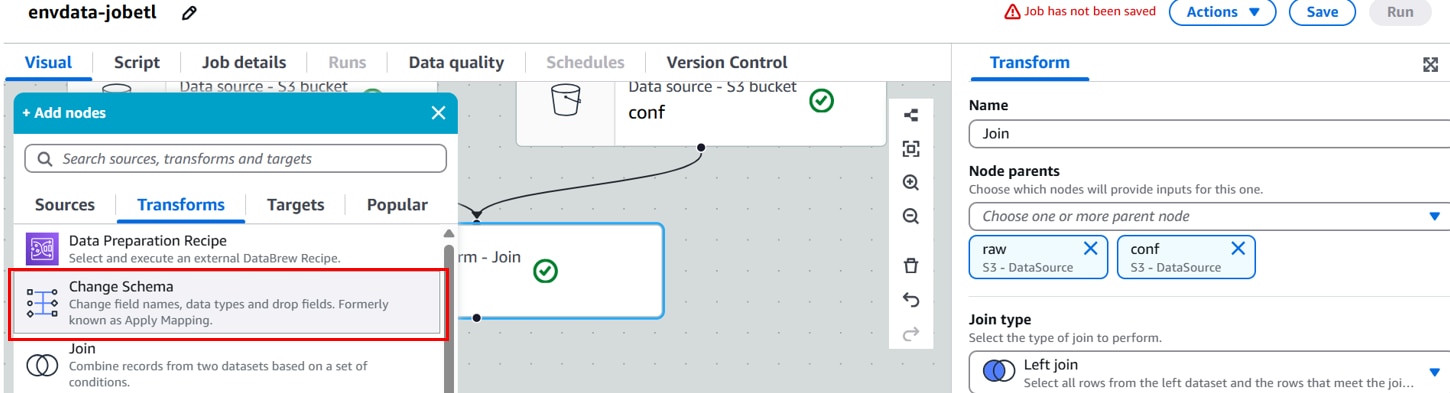
[Transform]を以下に設定します。
Name:Transform名。(例:Change Schema)
Node parents:親ノード。(例:Join Transformノード)
Change Schema:スキーマ変換条件。(例:timestampのData typeをstringからtimestampに変更 )
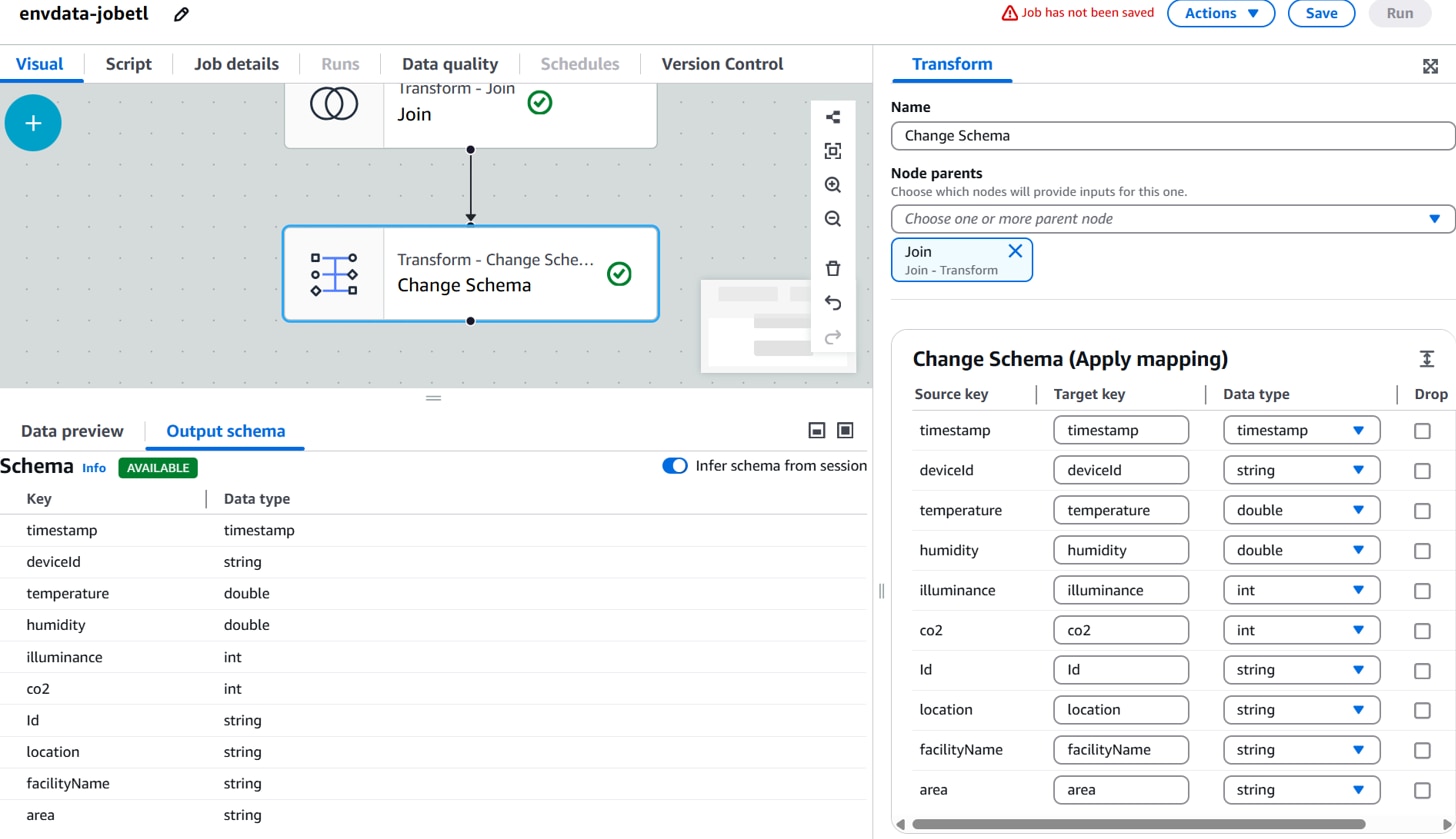
[Change Schema ]ノードを選択した状態で、「+」、[Targets]「Amazon S3」をクリックします。
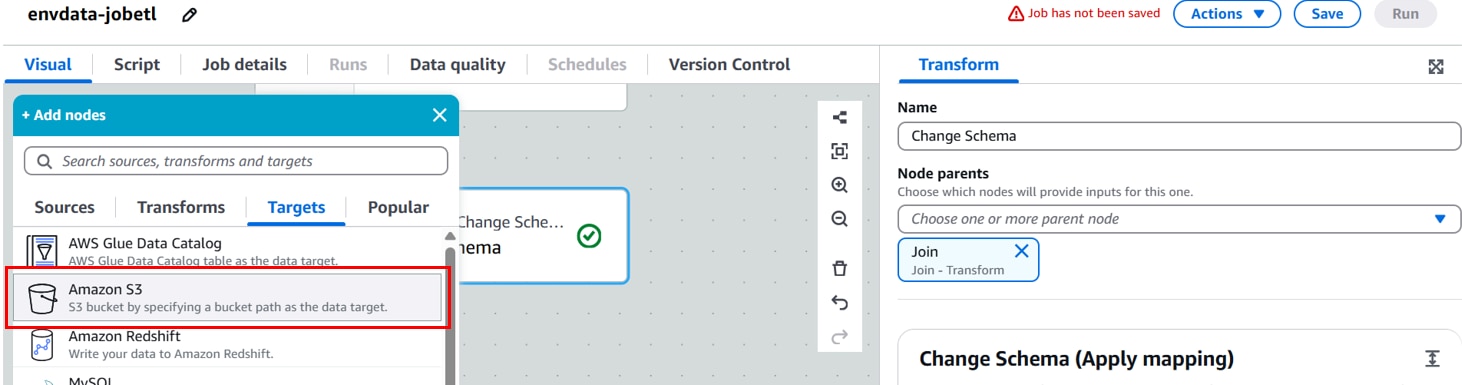
[Data target properties - S3]を以下に設定します。
Name:データターゲット名。(例:Join)
Node parents:親ノード。(例:Change Schemaノード)
Format:出力フォーマット。(例:CSV)
Compression Type:圧縮タイプ。(例:None)※デフォルト圧縮されるので圧縮したくない場合はNoneを選択。
S3 Target Location:加工データを格納するフォルダ。(例:s3://env-data-cnx/processed /)
Partition:deviceid
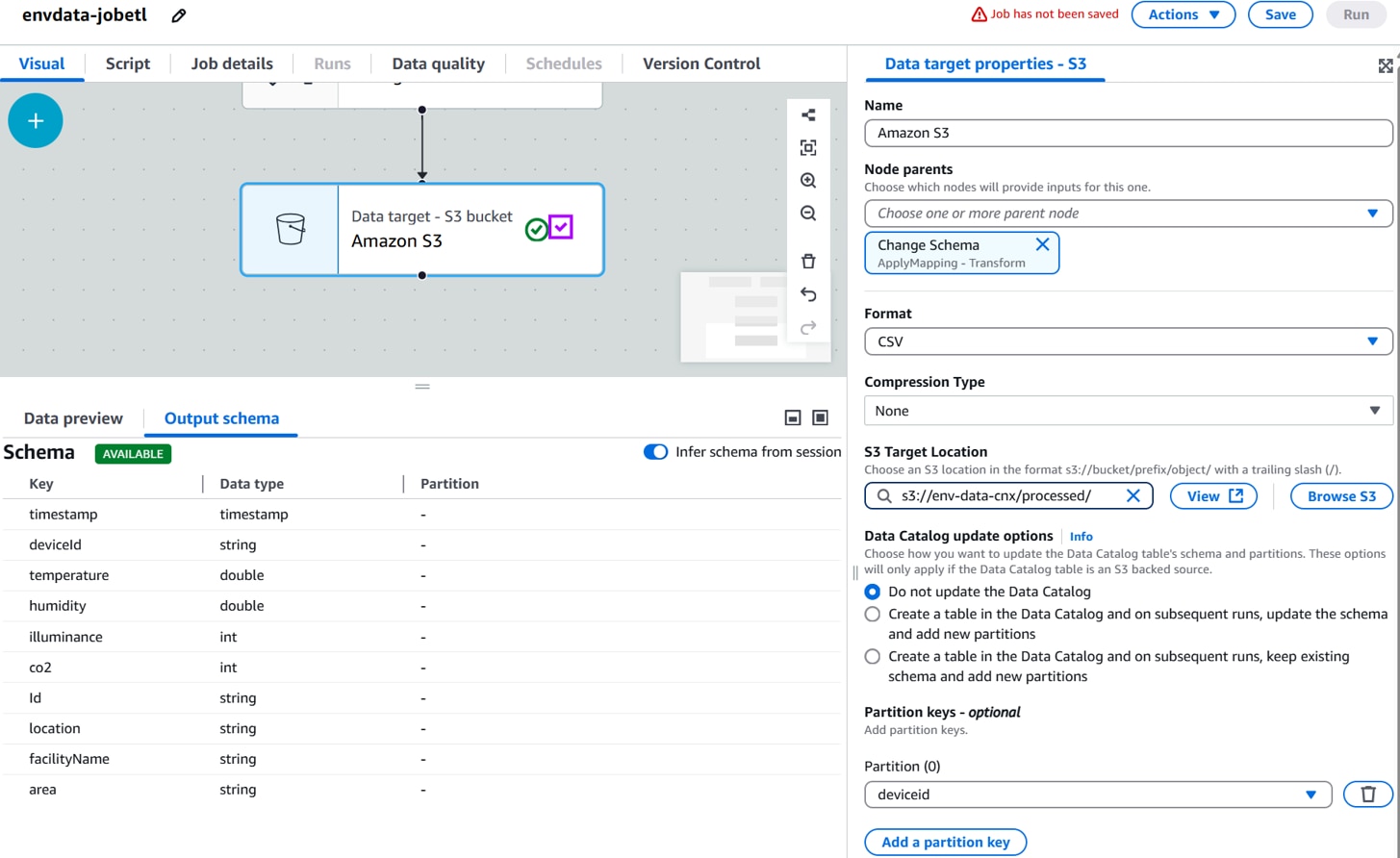
「Save」をクリックします。
GlueがS3にアクセスするためのIAM Roleの設定がされていないと、以下のようにエラーになります。
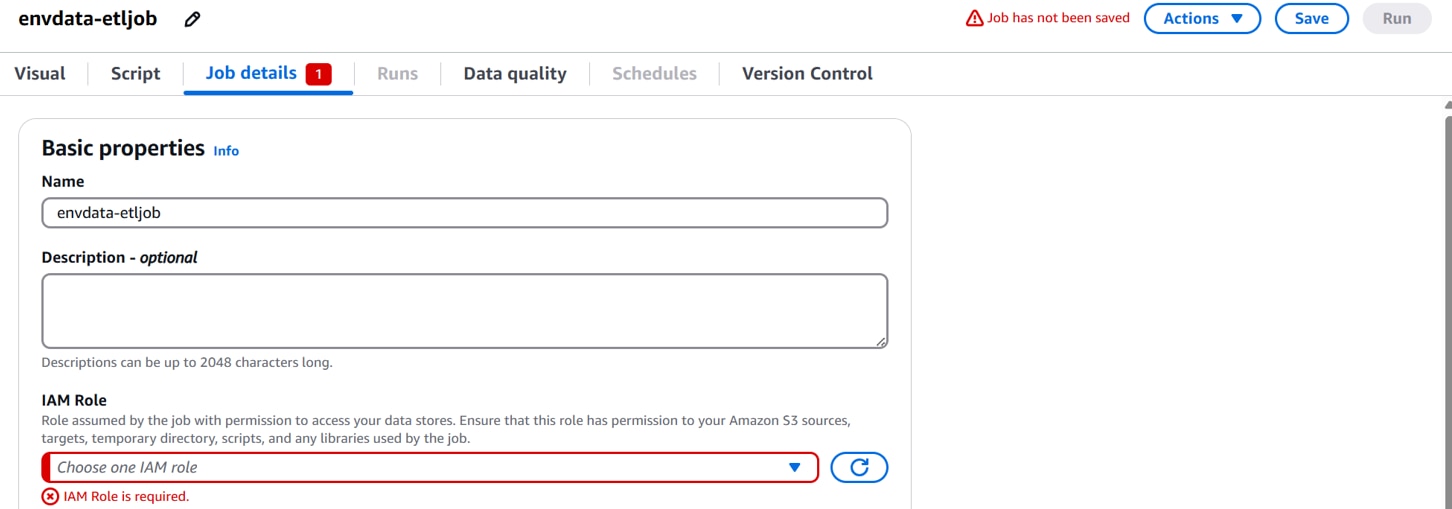
設定するIAM Roleを作成します。IAMコンソールを開き、「ロールを作成」をクリックします。

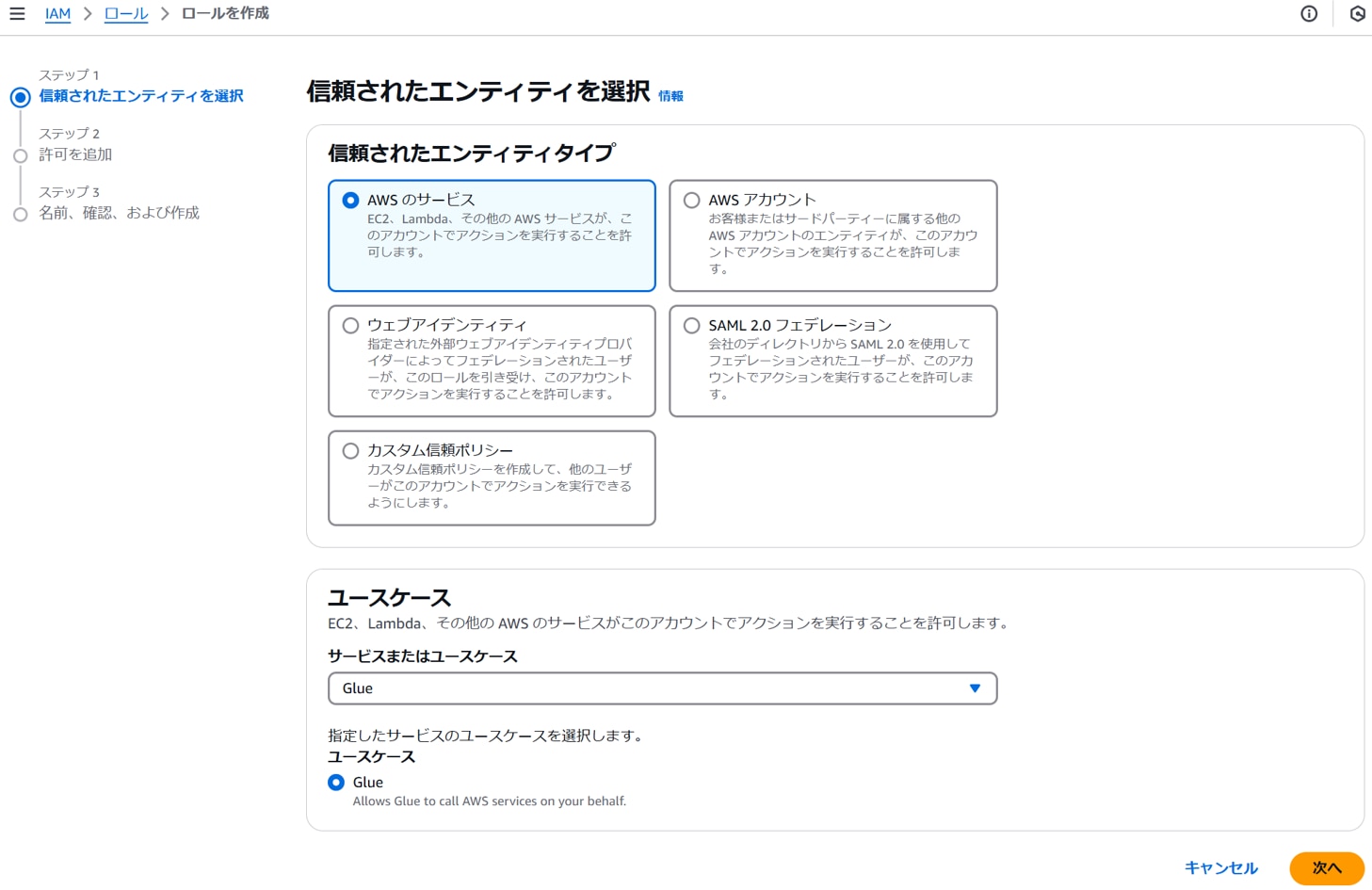
以下を設定し、「次へ」をクリックします。
信頼されたエンティティタイプ:AWSのサービス
[ユースケース]サービスまたはユースケース:Glue
以下のポリシーを追加し、「次へ」をクリックします。
ポリシー名:AmazonS3FullAcess
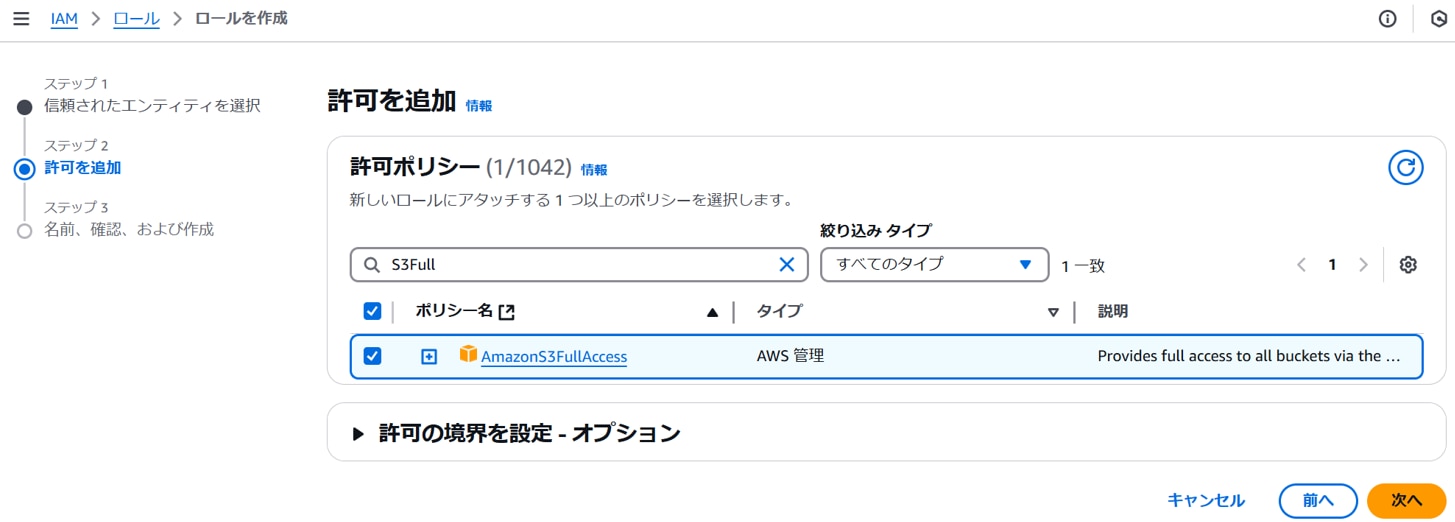
以下を設定し、「次へ」をクリックします。
ロール名:任意のロール名。(例:Glue-S3-FullAcess)
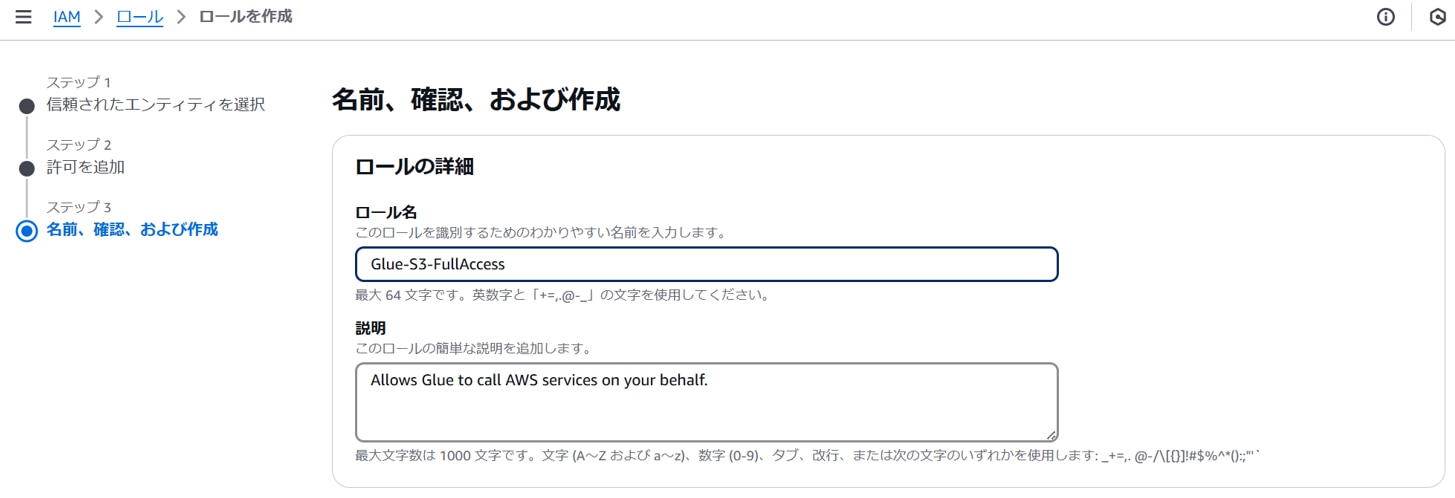
「ロールを作成」をクリックします。
ロールが作成されます。

Glueコンソールへ戻り、[Job details]タブで以下を設定し、「Save」をクリックします。
IAM Role:Glue-S3-FullAcess
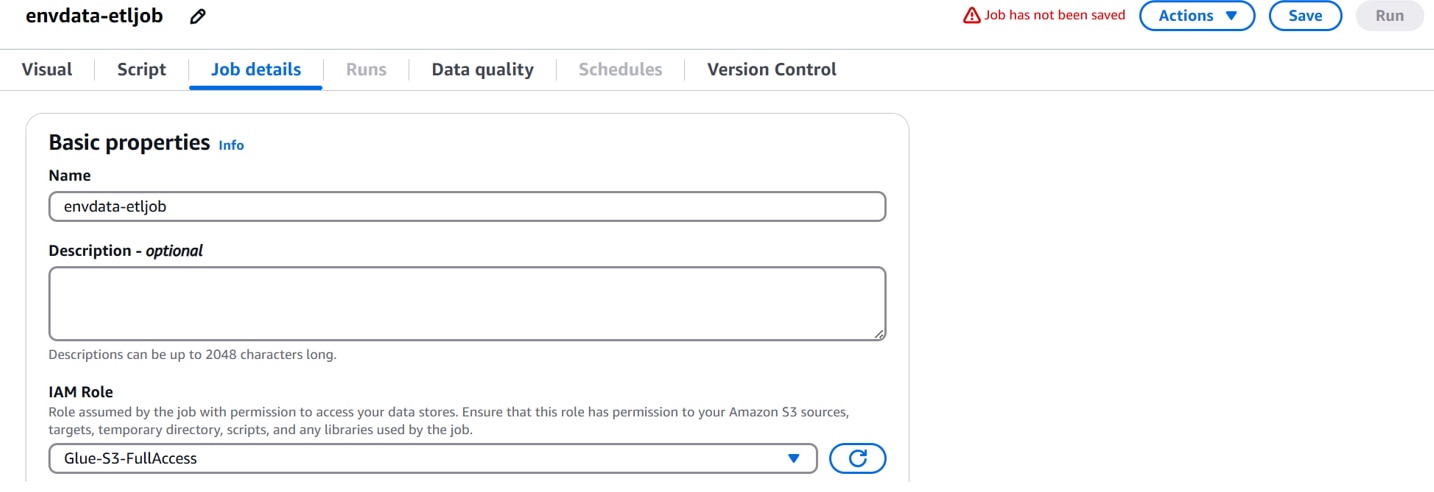
保存が成功します。
イベント起動確認
前手順でGlue Job(ETL)で、「Run」をクリックします。
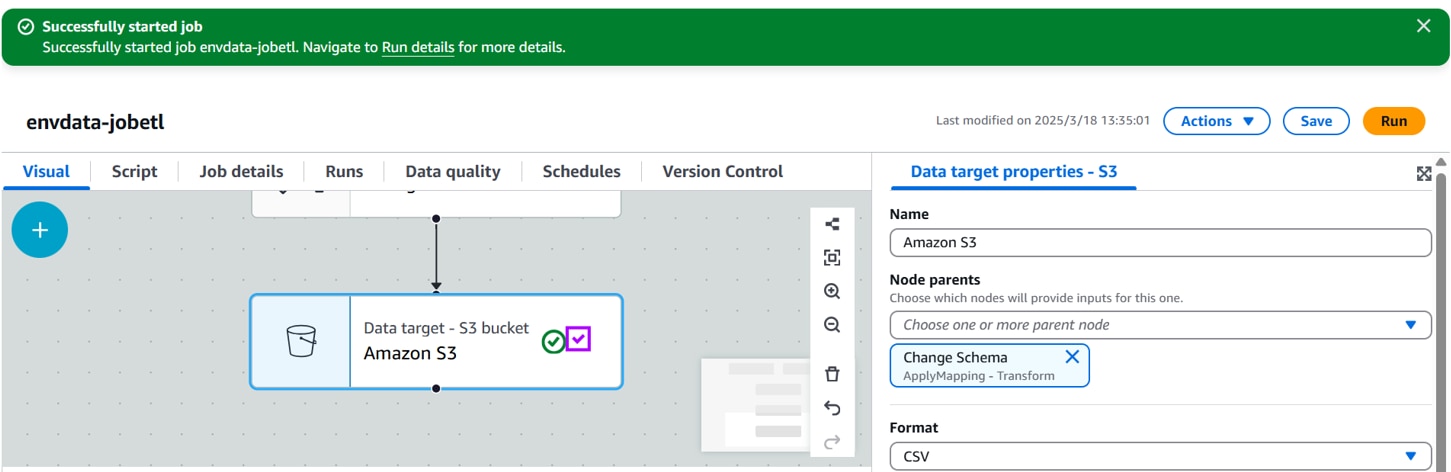
[Runs]タブにジョブの実行状態が表示されます。[Run status]が[Succeeded]になるまで待ちます。

ジョブ実行が成功すると、以下のように加工データ格納フォルダにCSVファイルが作成されます。
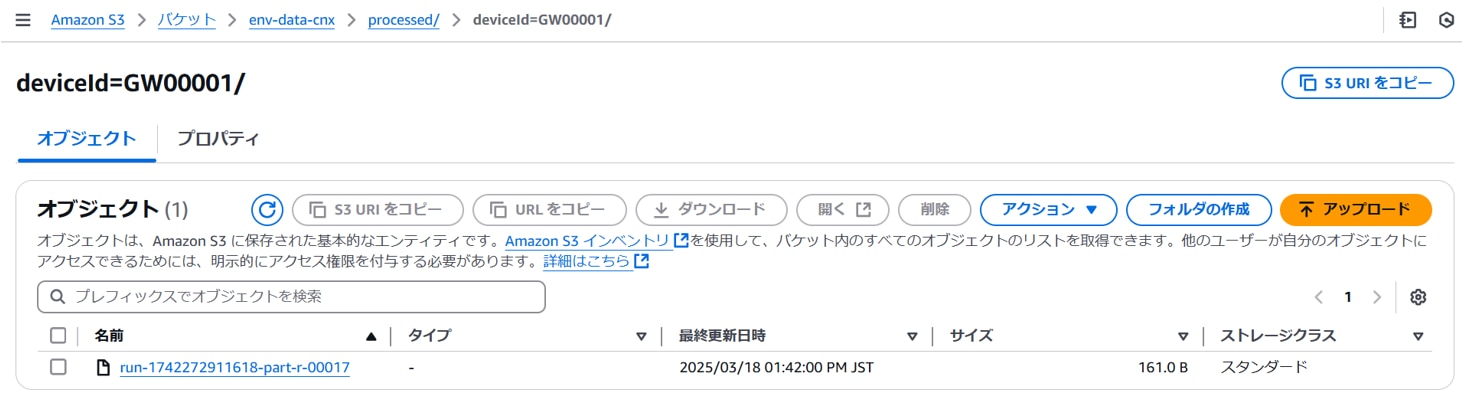
CSVファイルの内容を確認すると、データ加工が正常に行われています。

イベント起動の準備
以下のイベント起動部分の準備を行います。S3(raw)に生データ(JSON)が作成された際に、S3イベント通知を受け取りGlue Job(ETL)を実行するイベントをEventBridgeで作成します。
・S3バケットの通知設定
特定のS3バケットのイベントをAmazon EventBridgeに通知を送信するための設定を行います。
S3コンソールを開き、任意のバケットの[プロパティ][Amazon EventBridge]の「編集」をクリックします。

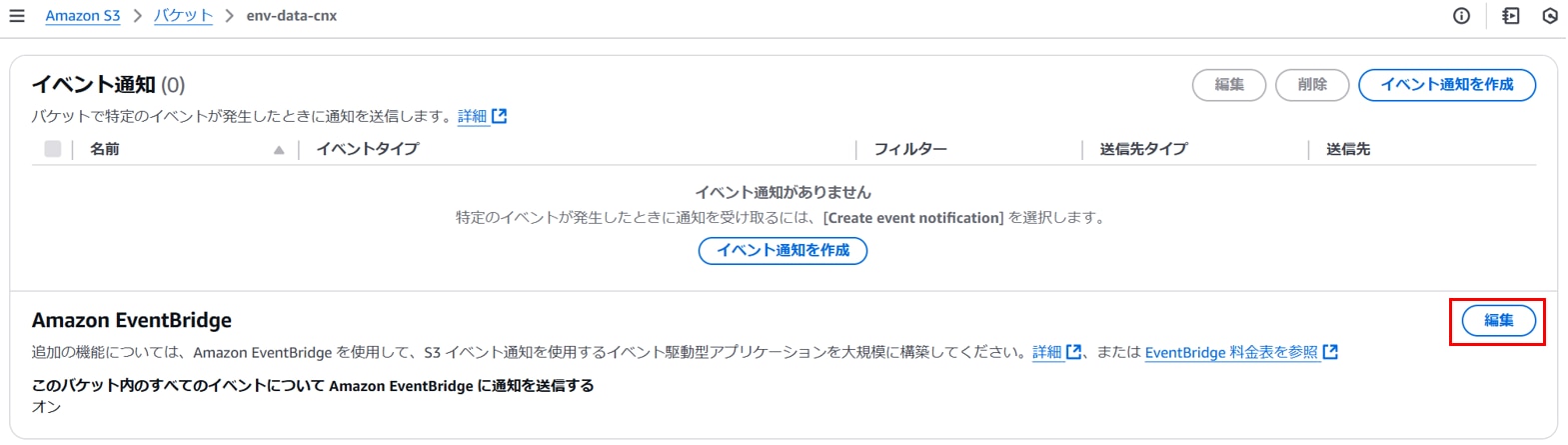
以下を設定し、「変更の保存」をクリックします。
このバケット内のすべてのイベントについてAmazon Bridgeに通知を送信する:オン 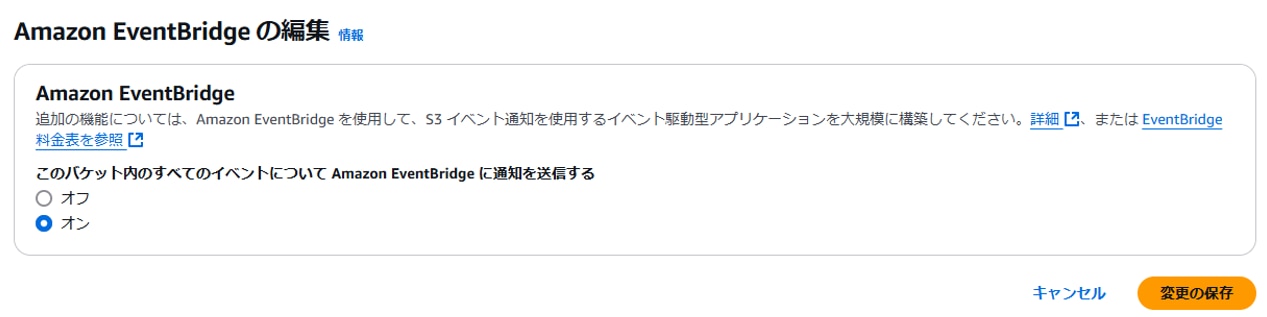
・Glueワークフローの作成
EventBridgeでS3イベント通知を受信した際に実行されるGlueワークフローを作成します。
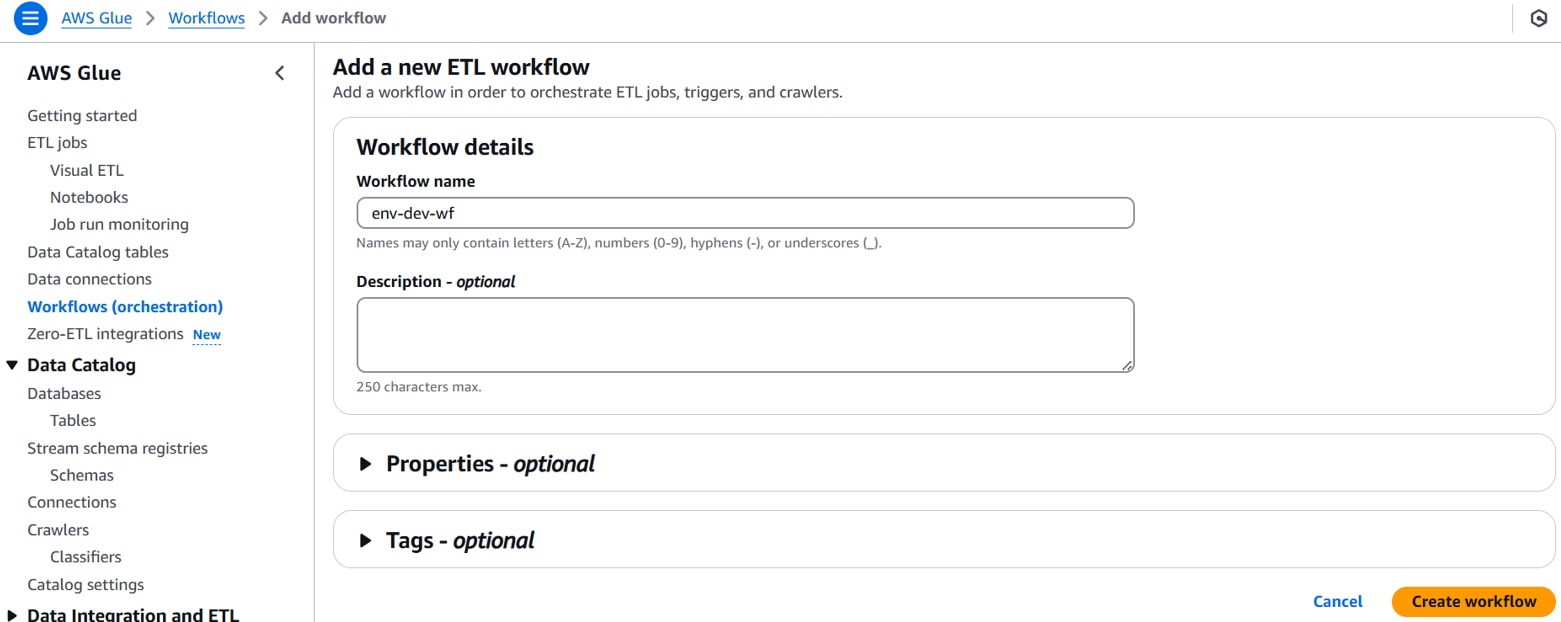
Glueコンソールを開き、[Workflows]で以下を設定し、 「Create workflow」をクリックします。
Workflow name:ワークフロー名(例:env-dev-wf)
Glueワークフローが作成されます。
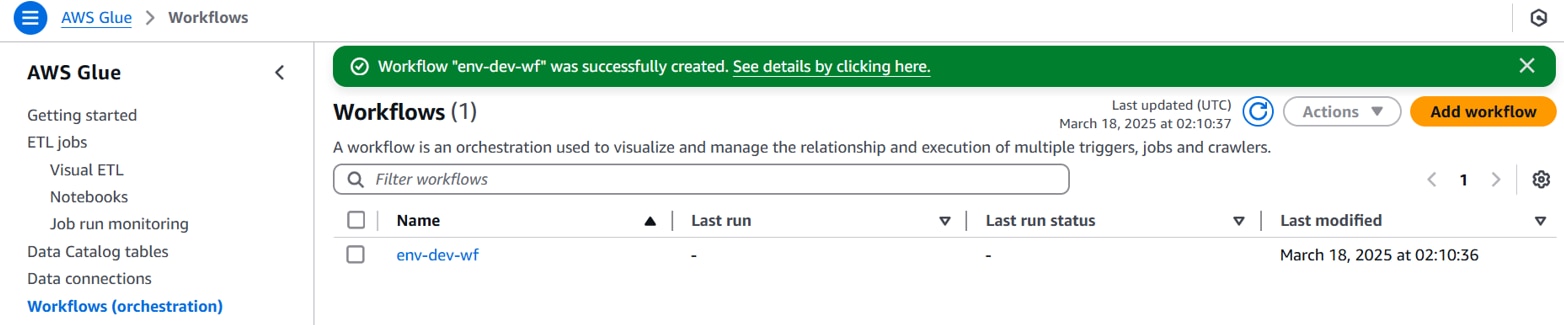
EventBridgeでイベント実行時にGlueトリガーを作成します。
Glueコンソールを開き、[Workflows]で前手順で作成したワークフローの設定で「Add trigger」をクリックします。
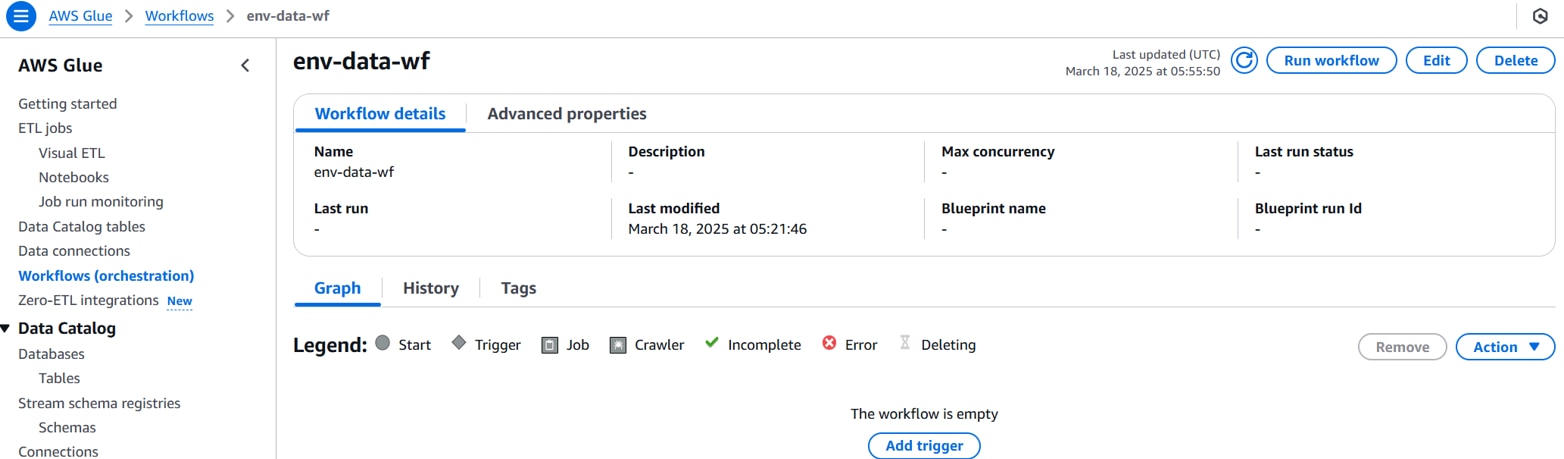
[Add new]タブで、以下を設定して「Add」をクリックします。
Name:トリガー名(例:env-data-glue-trigger)
Trigger type:EventBridge event
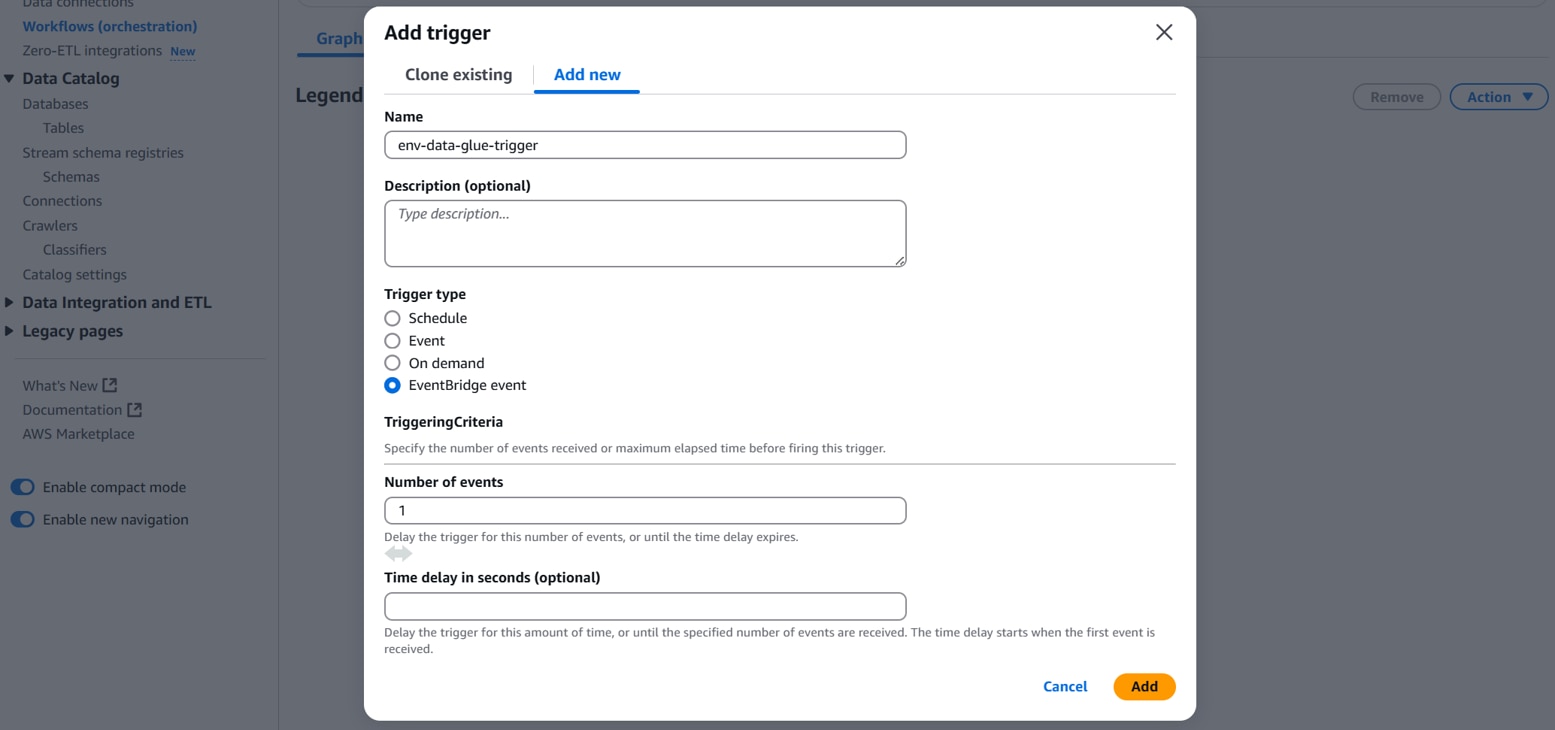
[Graph]タブの[Add node]をクリックします。 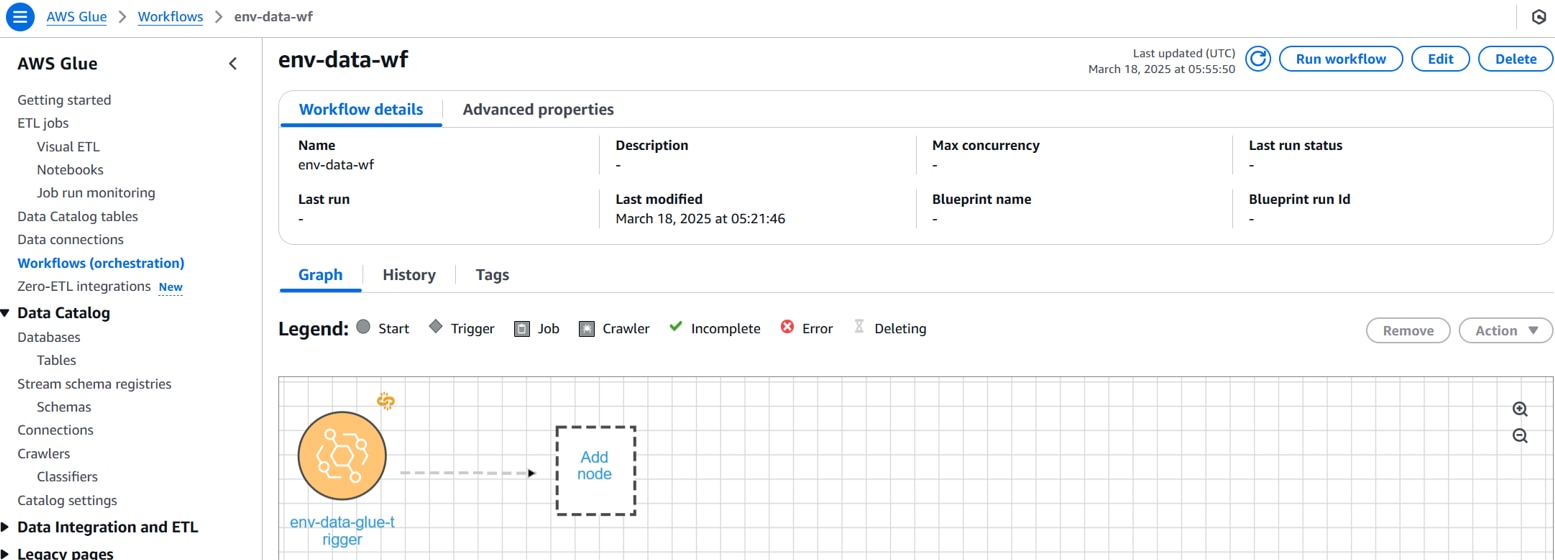
前手順で作成したGlue Job(ETL)を選択して「Add」をクリックします。
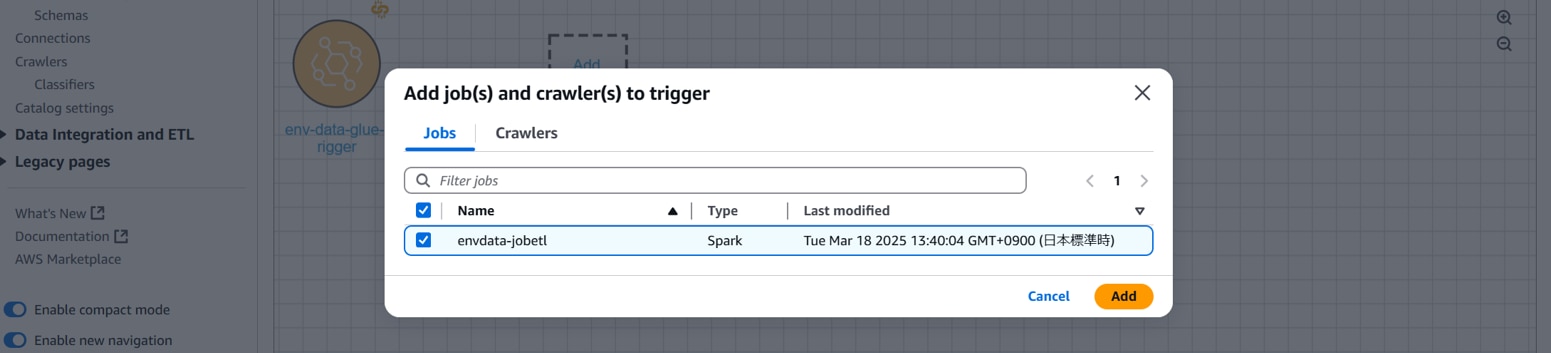
Glue Job(ETL)がノードに追加されます。
「Run workflow」をクリックします。
ワークフローが開始されます。
・EventBridgeルールの設定
EventBridgeでS3イベント通知を受信した際に前手順で作成したGlueワークフローを実行するための設定をします。
EventBridgeコンソールを開き、[ルール]「ルールを作成」をクリックします。
以下を設定して「次へ」をクリックします。
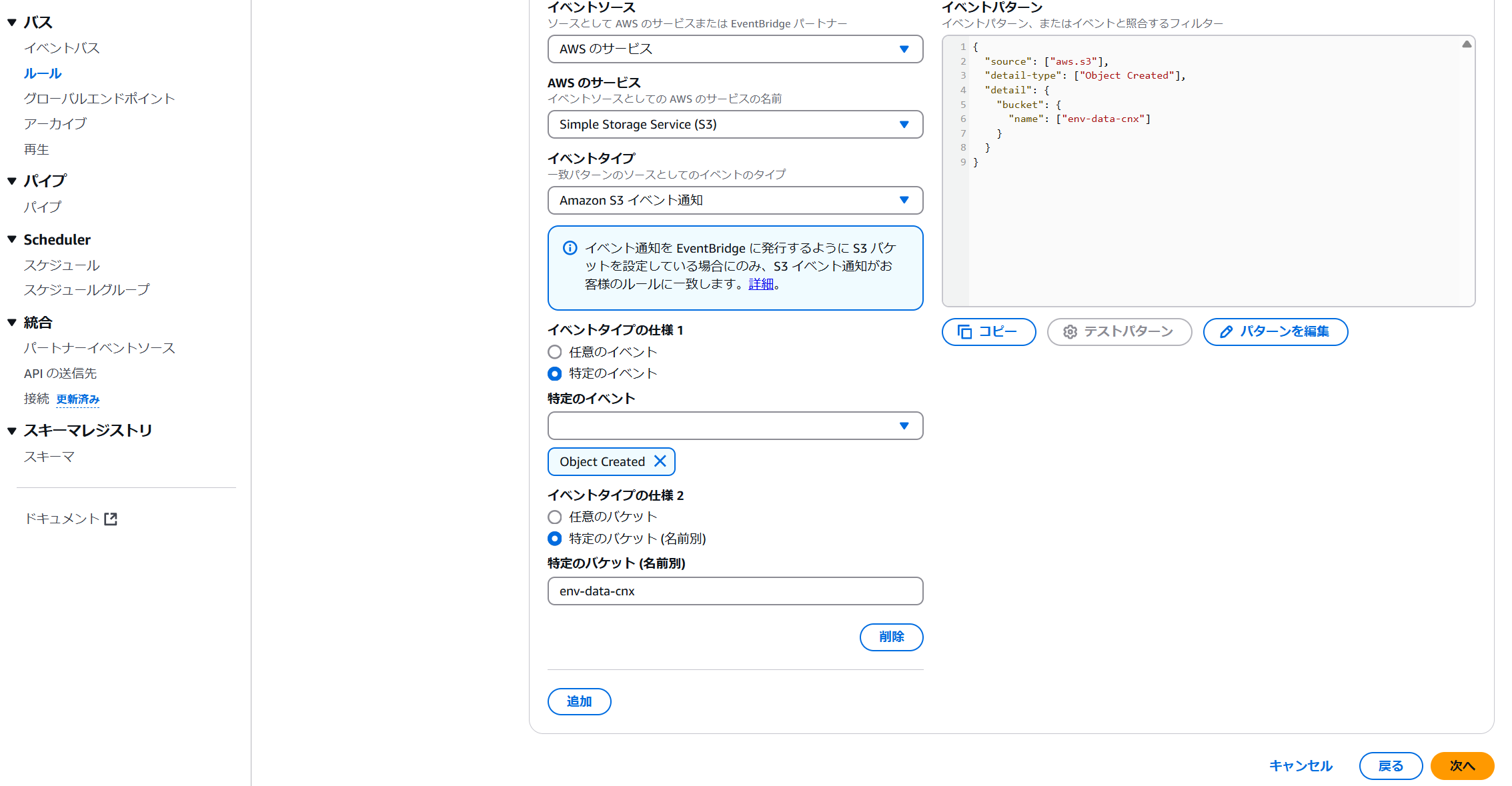
名前:ルール名(例:env-data-eb-rule)
ルールタイプ:イベントパターンを持つルール
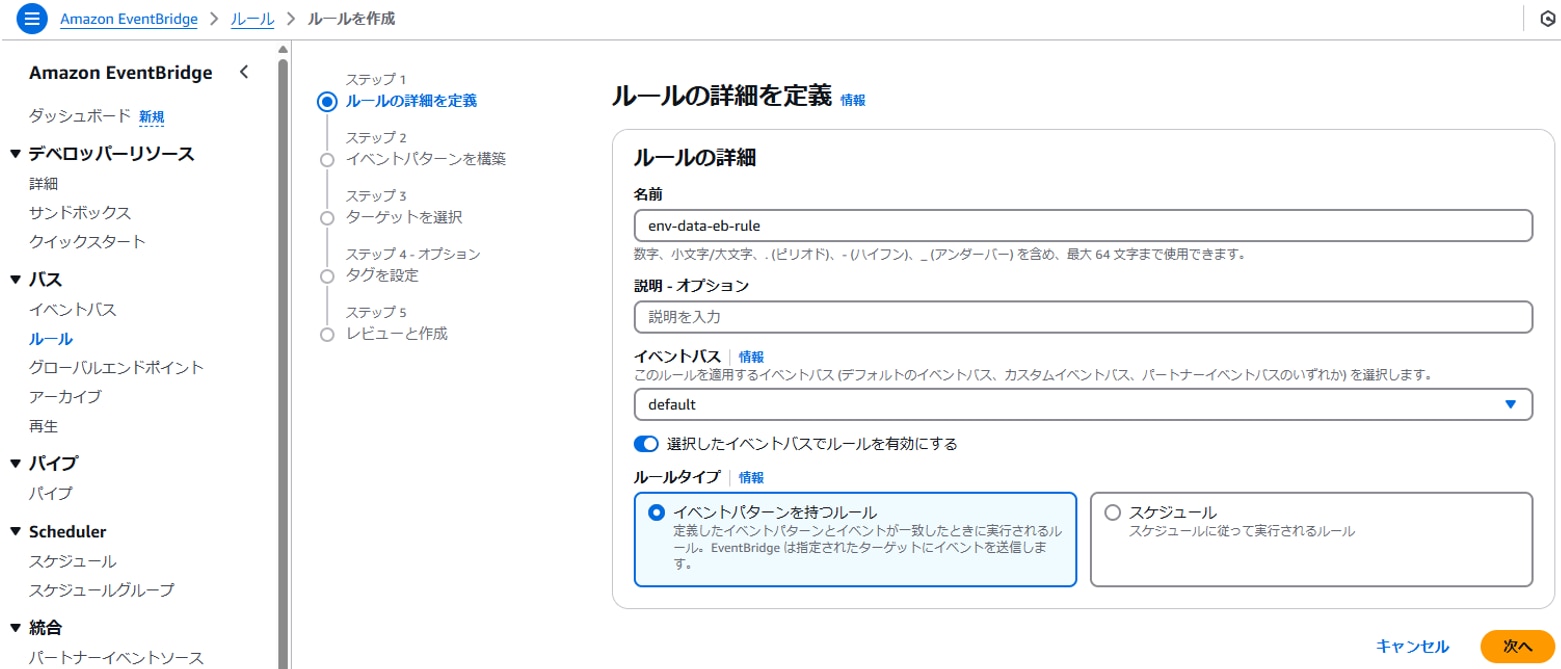
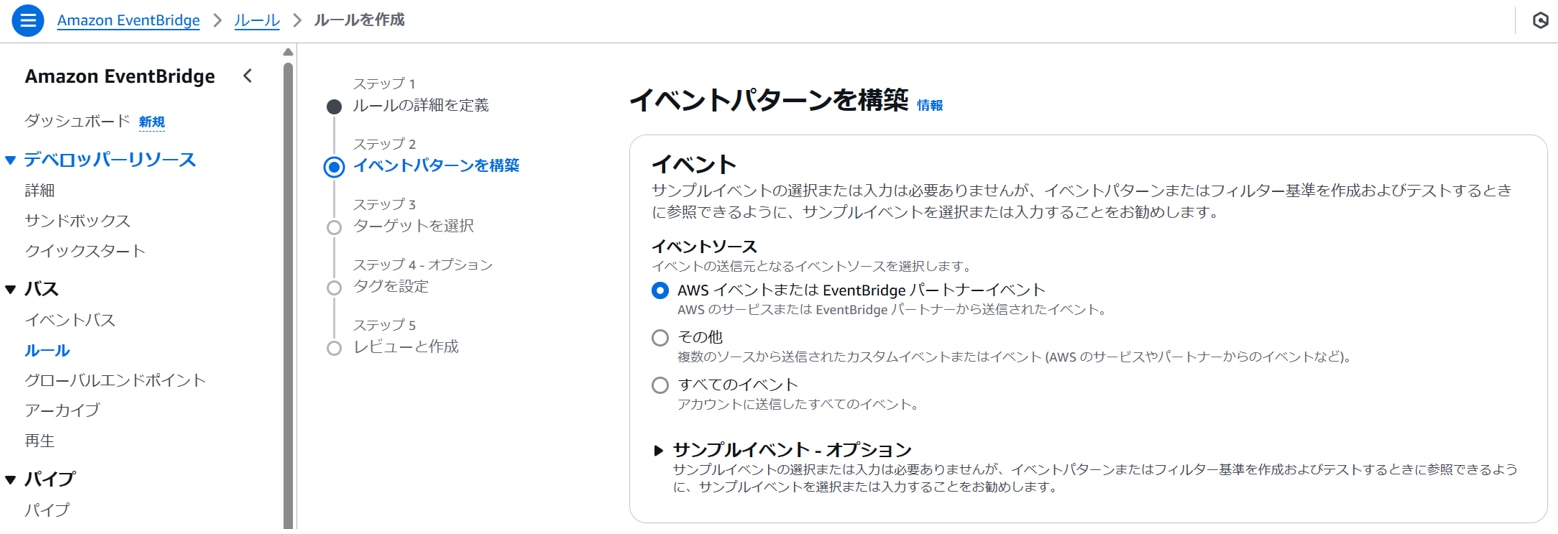
以下を設定します。
[イベント]イベントソース:AWSイベントまたはEventBridgeパートナーイベント
[イベントパターン]作成のメソッド:パターンフォームを使用する
イベントソース:AWSのサービス
AWSのサービス:Simple Storage Service(S3)
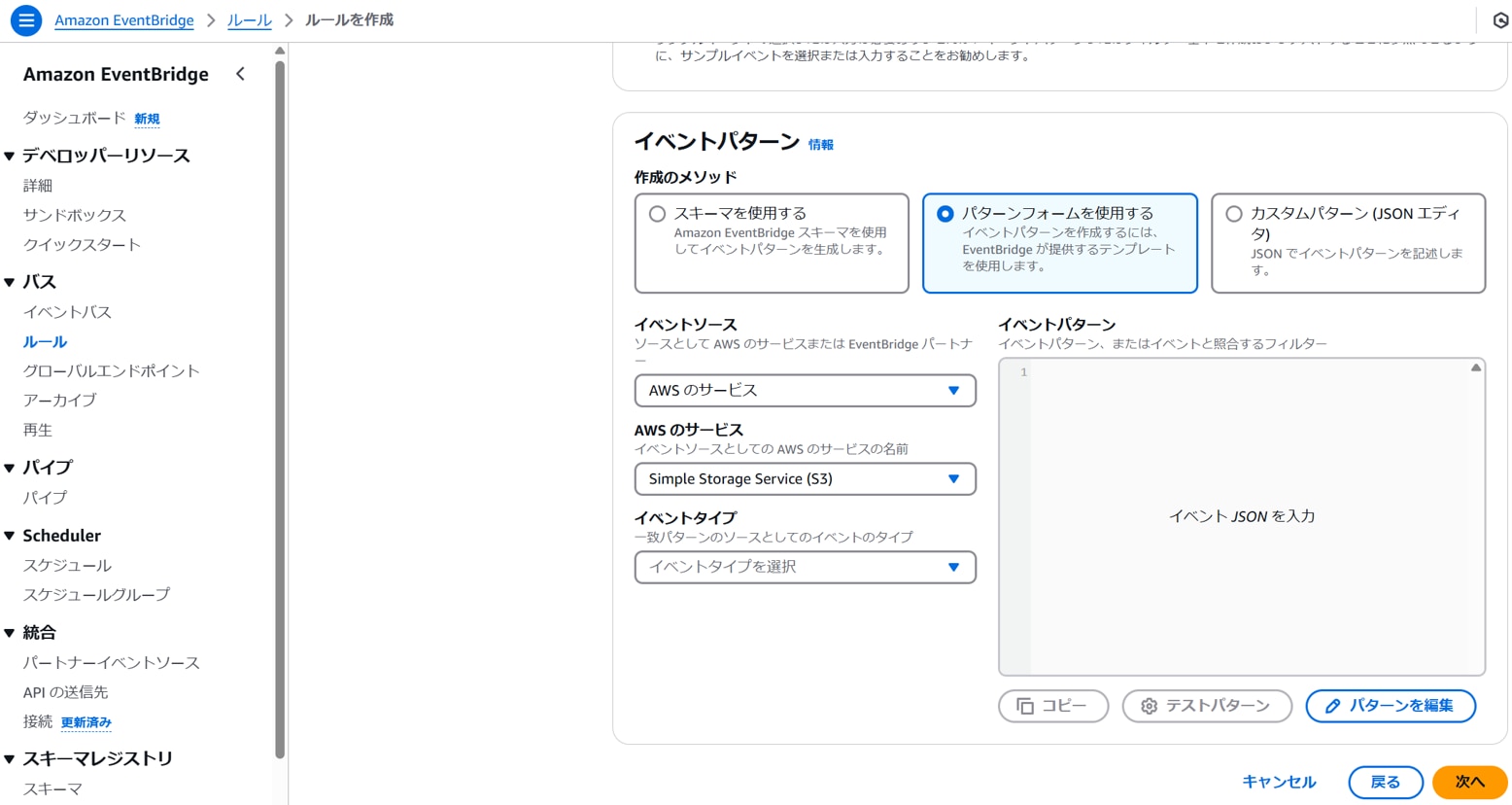
以下を設定します。
イベントタイプ:Amazon S3 イベント通知
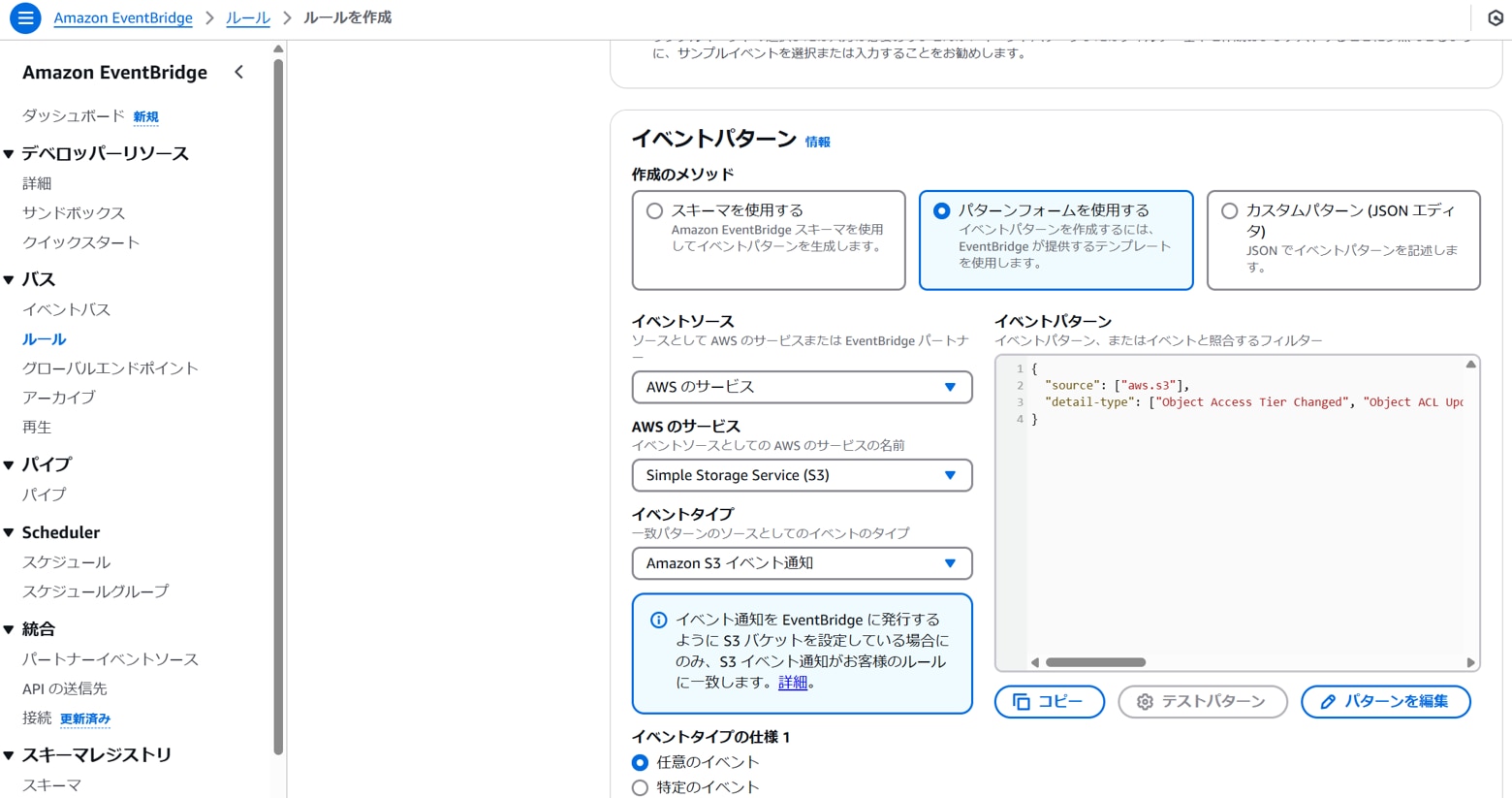
以下を設定します。
イベントタイプの仕様1(特定のイベント):Object Created
イベントタイプの仕様2(特定のバケット):任意のバケット(例:env-data-cnx)
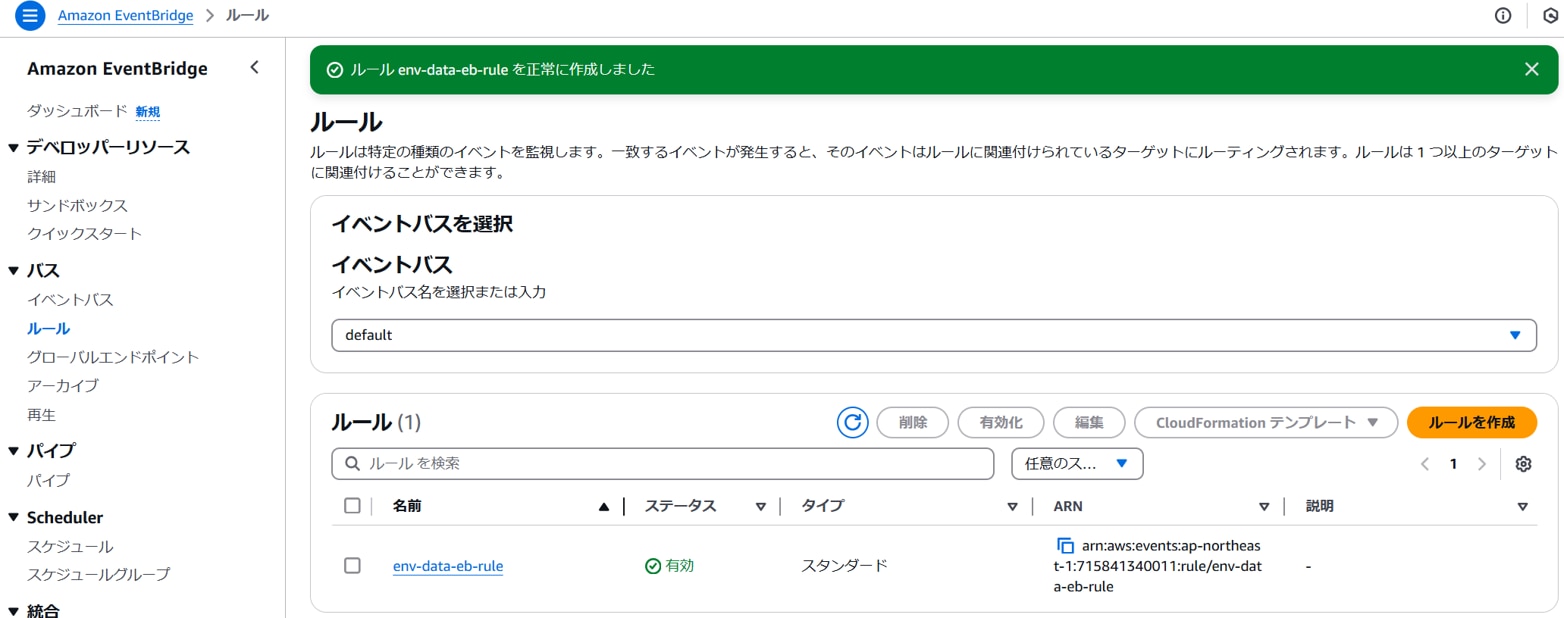
「ルールの作成」をクリックします。

ルールが作成されます。
イベント起動確認
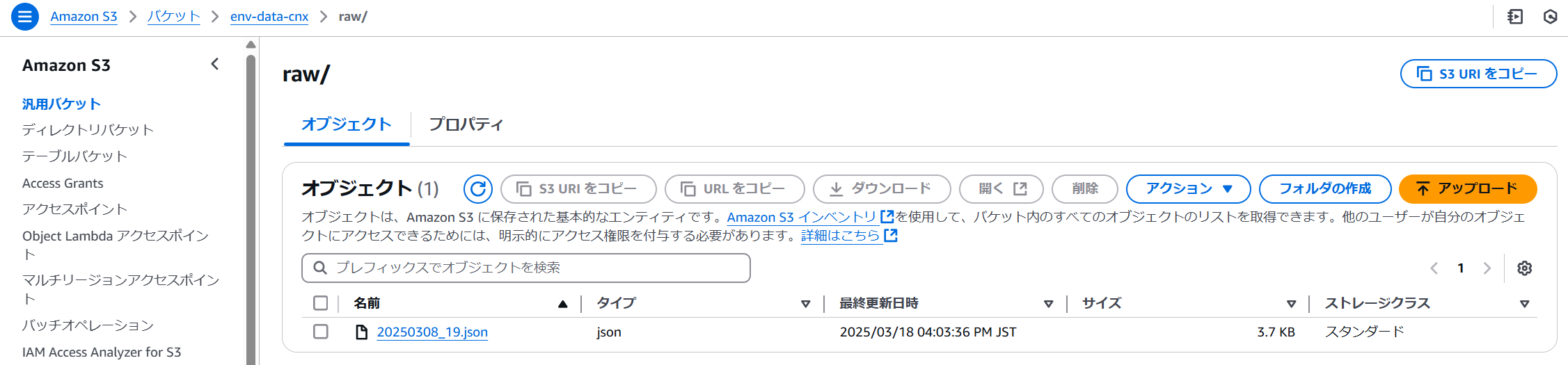
前手順で準備したイベント起動が正常に動作するか確認します。
生データ格納フォルダに以下のようなファイル(例:20250308_19.json※一部抜粋)をアップロードします。
自動でイベント起動され、加工データが作成されます。

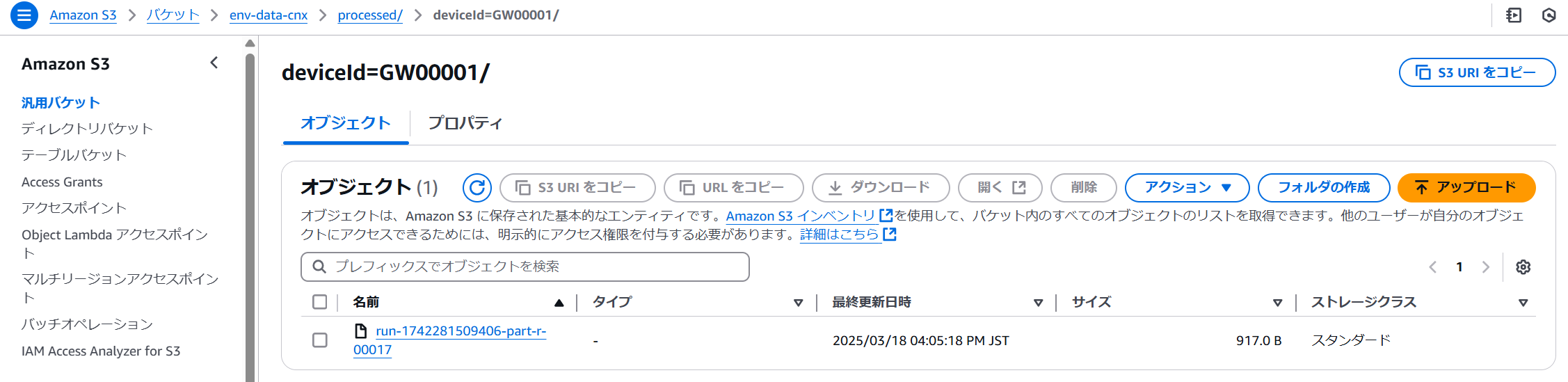
加工データ格納フォルダに以下のようなファイル(例:run-1742281509406-part-r-00017)が作成されます。
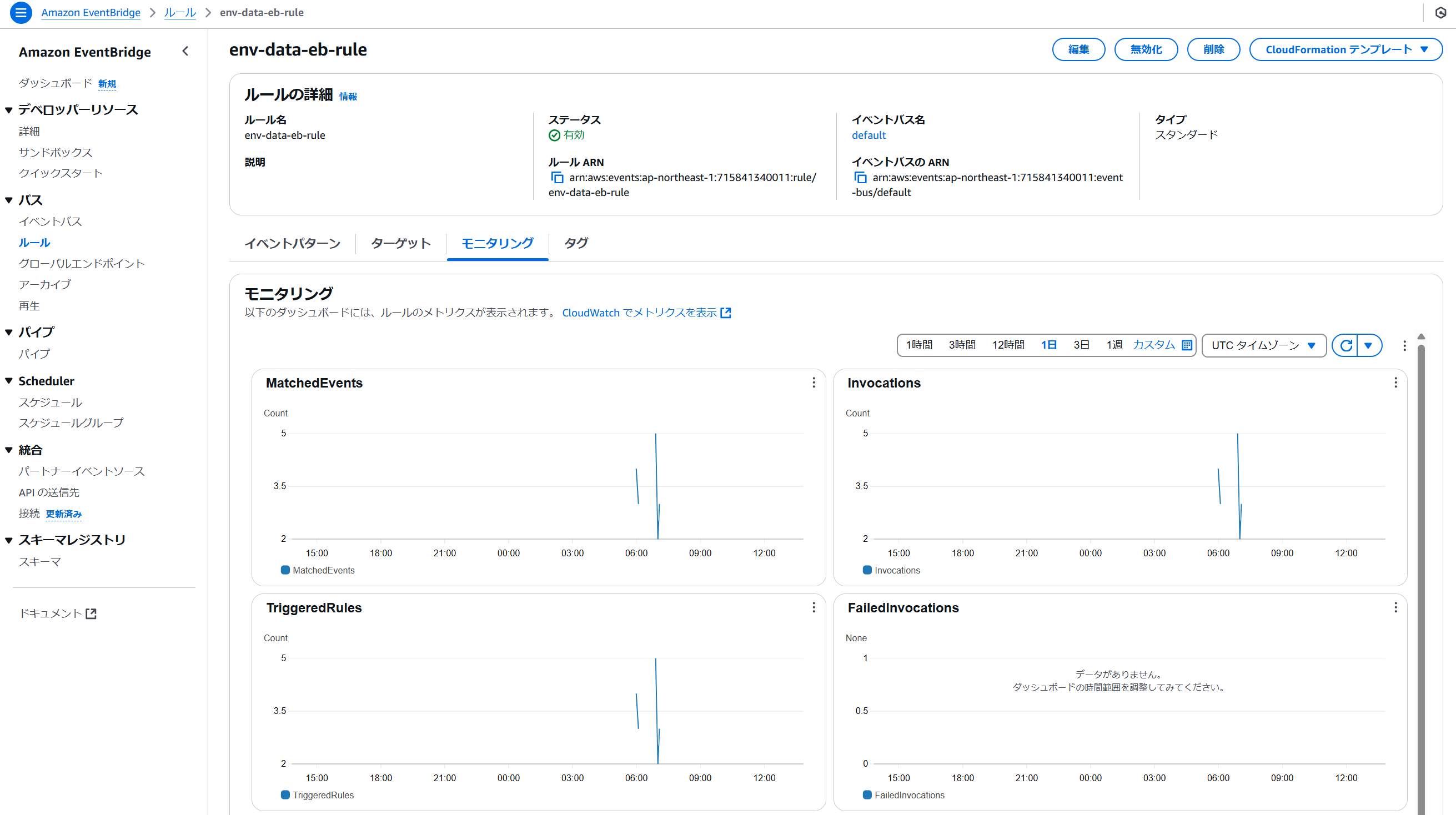
EventBridgeのルールの[モニタリング]タブで、MatchedEventsや、TriggeredRulesの発生記録を見ることができます。
まとめ
前編では、データ加工の準備と、その加工をイベントで起動するためのセットアップを行いました。データ加工の実装については、コスト面を考慮するとLambdaを活用するケースが多いですが、Glue Job(ETL)はGUIを活用することで直感的かつ視覚的にデータを操作できる点が大きな魅力ですね。
後編では、Athenaで取得したクエリ結果をQuickSightで可視化する準備と、それに伴う動作確認を行います。次回もぜひお楽しみに!
▶後編は コチラから!
▼オススメ関連記事
「 工事不要でIoTをお手軽導入!「EDConnectワイヤレス」とは?」
「 IoTに必須のIoTセンサの種類と特長、活用事例を解説 」
▼EDconnectワイヤレスの資料ダウンロードはこちらから